|
Millepede-II V04-17-06
|
|
Millepede-II V04-17-06
|
Linear Least Squares Fits with a Large Number of Parameters
Linear least squares problems. The most important general method for the determination of parameters from measured data is the linear least squares method. It is usually stable and accurate, requires no initial values of parameters and is able to take into account all the correlations between different parameters, even if there are many parameters.
Global and local parameters. The parameters of a least squares problem can sometimes be distinguished as global and local parameters. The mathematical model underlying the measurement depends on both types of parameters. The interest is in the determination of the global parameters, which appear in all the measurements. There are many sets of local parameters, where each set appears only in one, sometimes small, subset of measurements.
Alignment of large detectors in particle physics. Alignment problems for large detectors in particle physics often require the determination of a large number of alignment parameters, typically of the order of 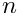 to
to 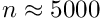 , but sometimes above
, but sometimes above 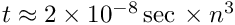 . Alignment parameters for example define the accurate space coordinates and orientation of detector components. In the alignment usually special alignment measurements are combined with data of particle reaction, typically tracks from physics interactions and from cosmics. In this paper the alignment parameters are called global parameters. Parameters of a single track like track slopes and curvatures are called local parameters.
. Alignment parameters for example define the accurate space coordinates and orientation of detector components. In the alignment usually special alignment measurements are combined with data of particle reaction, typically tracks from physics interactions and from cosmics. In this paper the alignment parameters are called global parameters. Parameters of a single track like track slopes and curvatures are called local parameters.
One approximate alignment method is to perform least squares fits on the data e.g. of single tracks assuming fixed alignment parameters. The residuals, the deviations between the fitted and measured data, are then used to estimate the alignment parameters afterwards. Single fits depend only on the small number of local parameters like slope or curvature of the track, and are easy to solve. This approximate method however is not a correct method, because the (local) fits depend on a wrong model, they ignore the global parameters, and the result are biased fits. The adjustment of parameters based on the observed (biased) residuals will then result in biased alignment parameters. If these alignment parameters are applied as corrections in repeated fits, the remaining residuals will be reduced, as desired. However, the fitted parameters will still be biased. In practice this procedure is often applied iteratively; it is however not clear wether the procedure is converging.
A more efficient and faster method is an overall least squares fit, with all the global parameters and local parameters, perhaps from thousands or millions of events, determined simultaneously. The Millepede algorithm makes use of the special structure of the least squares matrices in such a simultaneous fit: the global parameters can be determined from a matrix equation, where the matrix dimension is given by the number of global parameters only, irrespective of the total number of local parameters, and without any approximation. If 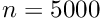 is the number of global parameters, then an equation with a symmetric -by- matrix has to be solved. The Millepede programm has been used for up to
is the number of global parameters, then an equation with a symmetric -by- matrix has to be solved. The Millepede programm has been used for up to 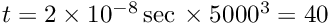 parameters in the past. Solution of the matrix equation was done with a fast program for the solution of matrix equations with inversion of the symmetric matrix, which on a standard PC takes a time
parameters in the past. Solution of the matrix equation was done with a fast program for the solution of matrix equations with inversion of the symmetric matrix, which on a standard PC takes a time 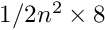 . Even for
. Even for 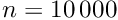 the computing time is, with
the computing time is, with 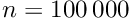 minutes, still acceptable.
minutes, still acceptable.
The next-generation detectors in particle physics however require up to about 100000 global parameters and with the previous solution method the space- and time-consumption is too large for a standard PC. Memory space is needed for the full symmetric matrix, corresponding to 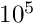 bytes for double precision, if the symmetry of the matrix is observed, and if solution is done in-space. This means memory space of 400 Mbyte and 40 Gbyte for
bytes for double precision, if the symmetry of the matrix is observed, and if solution is done in-space. This means memory space of 400 Mbyte and 40 Gbyte for 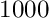 and
and 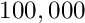 , and computing times of about 6 hours and almost a year, respectively.
, and computing times of about 6 hours and almost a year, respectively.
Millepede I and II. The second version of the Millepede programm, described here, allows to use several different methods for the solution of the matrix equation for global parameters, while keeping the algorithm, which decouples the determination of the local parameters, i.e. still taking into account all correlations between all global parameters. The matrix can be stored as a sparse matrix, if a large fraction of off-diagonal elements has zero content. A complete matrix inversion of a large sparse matrix would result in a full matrix, and would take an unacceptable time. Different methods can be used in Millepede II for a sparse matrix. The symmetric matrix can be accumulated in a special sparse storage scheme. Special solution methods can be used, which require only products of the symmetric sparse matrix with different vectors. Depending on the fraction of vanishing matrix elements, solutions for up to a number of 100000 global parameters should be possible on a standard PC.
The structure of Millepede II is different from the Millepede I version. The accumulation of data and the solution are splitted, with the solution in a stand-alone program. Furthermore the global parameters are now characterized by a label (any positive integer) instead of a (continuous) index. Those features should simplify the application of the program for alignment problems even for large number of global parameters in the range of 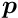 .
.
The solution of optimization problems requires the determination of certain parameters. In certain optimization problems the parameters can be classified as either global or local. This classification can be used, when the input data of the optimization problem consist out of a potentially large group of data sets, where the description of each single set of data requires certain local parameters, which appear only in the description of one data set. The global parameter may appear in all data sets, and the interest is in the determination of these global parameters. The local parameters can be called nuisance parameters.
An example for an optimization problem with global and local parameters from experimental high energy physics is the alignment of track detectors using a large number of track data. The track data are position measurements of a charged particle track, which can be fitted for example by a helix with five parameters, if the track detector is in a homogeneous magnetic field. The position measurement, from several detector planes of the track detector, depend on the position and orientation of certain sensors, and the corresponding coordinates and angles are global parameters. In an alignment the values of the global parameters are improved by minimizing the deviations between measurement and parametrization of a large number of tracks. Numbers of tracks in the order of one Million, with of the order of 10 data poinst per track, and of 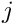 to
to 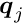 global parameters are typical for modern track detectors in high energy physics.
global parameters are typical for modern track detectors in high energy physics.
Optimal values of the global parameters require a simultaneous fit of all parameters with all data sets. A straight-forward ansatz for such a fit seems to require to fit Millions of parameters, which is impossible. An alternative is to perform each local fit separately, fitting the local parameters only. From the residuals of the local fits one can then try to fit the values of the global parameters. This approach neglects the correlations between the global and local parameters. Nevertheless the method can be applied iteratively with the hope, that the convergence is not to slow and does not require too many iterations.
The optimization problem is complicated by the fact, that often not all global parameters are defined by the ansatz. In the alignment example the degrees of freedom describing a translation and rotation of the whole detector are not fixed. The solution of the optimization problem requires therefore certain equality constraints, for example zero overall translation and rotation of the detector; these constraints are described by a linear combination of global parameters. Such an equality constraint can only be satisfied in an overall fit, not with separated local and global fits.
Global parameters are denoted by the vector 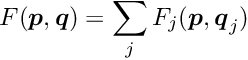 and local parameters for the data set
and local parameters for the data set 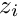 by the vector
by the vector 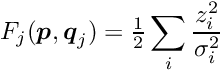 . The objective function to be minimized in the global parameter optimization is the sum of the local objective Function, depending on the global parameters and the vectors :
. The objective function to be minimized in the global parameter optimization is the sum of the local objective Function, depending on the global parameters and the vectors :
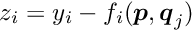
In the least squares method the objective function to be minimized is a sum of the squares of residuals 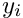 between the measured values and the parametrization, weighted by the inverse variance of the measured value:
between the measured values and the parametrization, weighted by the inverse variance of the measured value:
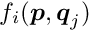
with the residual 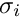 , where
, where 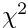 is the measured value and
is the measured value and  is the corresponding parametrization. This form of the objective function assumes independent measurements, with a single variance value
is the corresponding parametrization. This form of the objective function assumes independent measurements, with a single variance value 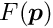 assigned.
assigned.
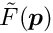 -function. In statistics there is a -distribution with a well-defined meaning. The minimum value
-function. In statistics there is a -distribution with a well-defined meaning. The minimum value 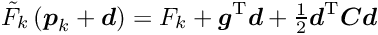 of the objective function follows, under certain conditions, the -distribution.
of the objective function follows, under certain conditions, the -distribution.The standard optimization method for smooth objective functions is the Newton method. The objective function 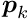 , depending on a parameter vector , is approximated by a quadratic model
, depending on a parameter vector , is approximated by a quadratic model 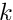
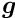
where 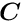 is the vector in the
is the vector in the 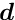 -th iteration and where the vector
-th iteration and where the vector 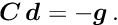 is the gradient of the objective function; the matrix
is the gradient of the objective function; the matrix 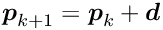 is the Hessian (second derivative matrix) of the objective function or an approximation of the Hessian. The minimum of the quadratic approximation requires the gradient to be equal to zero. A step
is the Hessian (second derivative matrix) of the objective function or an approximation of the Hessian. The minimum of the quadratic approximation requires the gradient to be equal to zero. A step 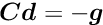 in parameter space is calculated by the solution of the matrix equation, obtained from the derivative of the quadratic model:
in parameter space is calculated by the solution of the matrix equation, obtained from the derivative of the quadratic model:
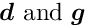
With the correction vector the new value 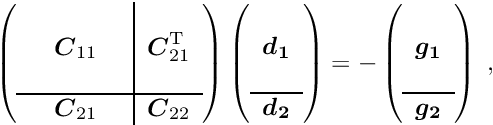 for the next iteration is obtained. The matrix is a constant in a linear least squares problem and the minimum is determined in a single step (no iteration necessary).
for the next iteration is obtained. The matrix is a constant in a linear least squares problem and the minimum is determined in a single step (no iteration necessary).
The special structure of the matrix in a matrix equation 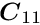 may allow a significant simplification of the solution. Below the symmetric matrix is partitioned into submatrices, and the vectors
may allow a significant simplification of the solution. Below the symmetric matrix is partitioned into submatrices, and the vectors 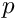 are partitioned into two subvectors; then the matrix equation can be written in the form
are partitioned into two subvectors; then the matrix equation can be written in the form
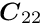
where the submatrix 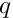 is a
is a 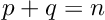 -by- square matrix and the submatrix
-by- square matrix and the submatrix 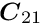 is a
is a 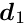 -by- square matrix, with
-by- square matrix, with 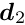 , and
, and 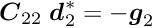 is a -by- matrix. Now it is assumed that the inverse of the -by- sub-matrix is available. In certain problems this may be easily calculated, for example if is diagonal.
is a -by- matrix. Now it is assumed that the inverse of the -by- sub-matrix is available. In certain problems this may be easily calculated, for example if is diagonal.
If the sub-vector 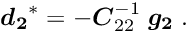 would not exist, the solution for the sub-vector
would not exist, the solution for the sub-vector 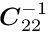 would be defined by the matrix equation
would be defined by the matrix equation 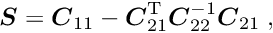 , where the star indicates the special character of this solution, which is
, where the star indicates the special character of this solution, which is
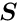
Now, having the inverse sub-matrix  , the submatrix of the complete inverse matrix correponding to the upper left part is the inverse of the symmetric -by- matrix
, the submatrix of the complete inverse matrix correponding to the upper left part is the inverse of the symmetric -by- matrix
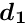
the so-called Schur complement. With this matrix 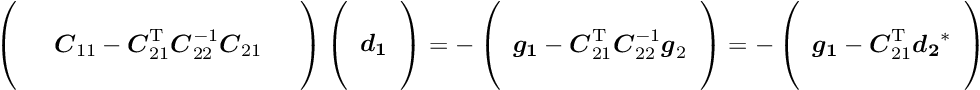 the solution of the whole matrix equation can be written in the form
the solution of the whole matrix equation can be written in the form
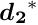
The sub-vector 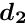 can be obtained from the solution of the matrix equation
can be obtained from the solution of the matrix equation
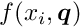
using the known right-hand-side of the equation with the special solution 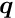 .
.
In a similar way the vector 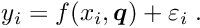 could be calculated. However, if the interest is the determination of this sub-vector only, while the sub-vector is not needed, then only the equation (4) has to be solved after calculation of the special solution (equation (2)) and the Schur complement (equation (3)). Some computer time can be saved by this method, especially if the matrix is easily calculated or already known before; note that the matrix does not appear directly in the solution, only the inverse .
could be calculated. However, if the interest is the determination of this sub-vector only, while the sub-vector is not needed, then only the equation (4) has to be solved after calculation of the special solution (equation (2)) and the Schur complement (equation (3)). Some computer time can be saved by this method, especially if the matrix is easily calculated or already known before; note that the matrix does not appear directly in the solution, only the inverse .
This method of removing unnecessary parameters was already known in the nineteenth century. The method can be applied repeatedly, and therefore may simplify the solution of problems with a large number of parameters. The method is not an approximation, but is exact and it takes into account all the correlations introduced by the removed parameters.
A set of local measured data is considered. The local data are assumed to be described by a linear or non-linear function 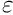 , depending on a (small) number of local parameters
, depending on a (small) number of local parameters 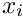 .
.
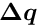
The parameters are called the local parameters, valid for the specific group of measurements (local-fit object). The quantity 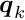 is the measurement error, with standard deviation . The quantity
is the measurement error, with standard deviation . The quantity 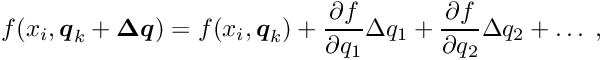 is assumed to be the coordinate of the measured value , and is one argument of the function .
is assumed to be the coordinate of the measured value , and is one argument of the function .
The local parameters are determined in a least squares fit. If the function depends non-linearly on the local parameters , an iterative procedure is used, where the function is linearized, i.e. the first derivatives of the function with respect to the local parameters are calculated. The function is thus expressed as a linear function of local parameter corrections 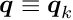 at some reference value
at some reference value 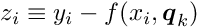 :
:
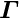
where the derivatives are calculated for 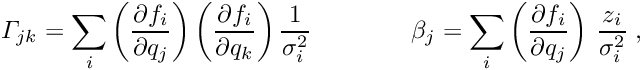 . For each single measured value, the residual measurement
. For each single measured value, the residual measurement
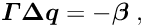
is calculated. For each iteration a linear system of equations (normal equations of least squares) has to be solved for the parameter corrections with a matrix 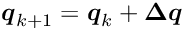 and a gradient vector with elements
and a gradient vector with elements
where the sum is over all measurements of the local-fit object. Corrections are determined by the solution of the matrix equation
and a new reference value is obtained by
and then, with increased by 1, this is repeated until convergence is reached.
Now global parameters are considered, which contribute to all the measurements. The expectation function (5) is extended to include corrections for global parameters. Usually only few of the global parameters influence a local-fit object. A global parameter is identified by a label 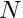 ; assuming that labels from a set
; assuming that labels from a set 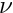 contribute to a single measurement the extended equation becomes
contribute to a single measurement the extended equation becomes
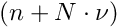
In the following it is assumed that there is a set of 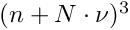 local measurements. Each local measurement, with index , depends on
local measurements. Each local measurement, with index , depends on 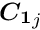 local parameters , and all of them depend on the global parameters. In a simultaneous fit of all global parameters plus local parameters from subsets of the data there are in total
local parameters , and all of them depend on the global parameters. In a simultaneous fit of all global parameters plus local parameters from subsets of the data there are in total 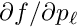 parameters, and the standard solution requires the solution of equations with a computation proportional to
parameters, and the standard solution requires the solution of equations with a computation proportional to 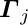 . In the next chapter it is shown, that the problem can be reduced to a system of equations, for the global parameters only.
. In the next chapter it is shown, that the problem can be reduced to a system of equations, for the global parameters only.
For a set of local measurements one obtains a system of least squares normal equations with large dimensions, as is shown in equation (7) The matrix on the left side of equation (7) has, from each local measurement, three types of contributions. The first part is a contribution of a symmetric matrix 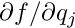 , of dimension (number of global parameters), and is calculated from the (global) derivatives
, of dimension (number of global parameters), and is calculated from the (global) derivatives 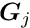 . All the matrices are added up in the upper left corner of the big matrix of the normal equations. The second contribution is the symmetric matrix
. All the matrices are added up in the upper left corner of the big matrix of the normal equations. The second contribution is the symmetric matrix 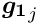 (compare equation (6)), which gives a contribution to the big matrix on the diagonal and is depending only on the -th local measurement and the (local) derivatives
(compare equation (6)), which gives a contribution to the big matrix on the diagonal and is depending only on the -th local measurement and the (local) derivatives 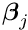 . The third (mixed) contribution is a rectangular matrix
. The third (mixed) contribution is a rectangular matrix 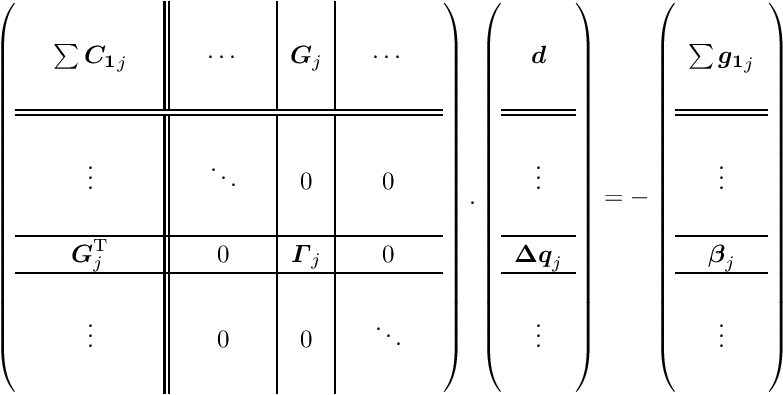 , with a row number of (global) and a column number of (local). There are two contributions to the vector of the normal equations (gradient),
, with a row number of (global) and a column number of (local). There are two contributions to the vector of the normal equations (gradient), 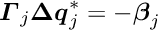 for the global and
for the global and  for the local parameters. The complete matrix equation is given by
for the local parameters. The complete matrix equation is given by
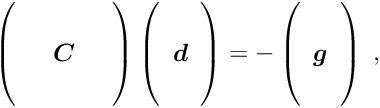
In this matrix equation the matrices , , and the vectors and contain contributions from the -th local measurement. Ignoring the global parameters (i.e. keeping them constant) one could solve the normal equations  for each local measurement separately by
for each local measurement separately by
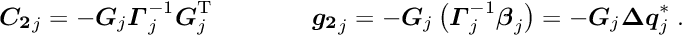
The complete system of normal equations has a special structure, with many vanishing sub-matrices. The only connection between the local parameters of different partial measurements is given by the sub-matrices und ,
The aim of the fit is solely to determine the global parameters; final best parameters of the local parameters are not needed. The matrix of equation (7) is written in a partitioned form. The general solution can also be written in partitioned form. Many of the sub-matrices of the huge matrix in equation (7) are zero and this has the effect, that the formulas for the sub-matrices of the inverse matrix are very simple.
By this procedure the normal equations
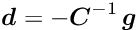
are obtained, which only contain the global parameters, with a modified matrix and a modified vector ,
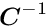
with the following local contributions to and from the -th local fit:
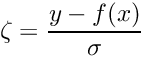
The set of normal equations (8) contains explicitly only the global parameters; implicitly it contains, through the correction matrices, the complete information from the local parameters, influencing the fit of the global parameters. The parentheses in equation (9) represents the solution for the local parameters, ignoring the global parameters. The solution
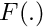
represents the solution vector with covariance matrix  . The solution is direct, no iterations or approximations are required. The dimension of the matrix to compute from equation (1) is reduced from to . The vector is the correction for the global parameter vector . Iterations may be necessary for other reasons, namely
. The solution is direct, no iterations or approximations are required. The dimension of the matrix to compute from equation (1) is reduced from to . The vector is the correction for the global parameter vector . Iterations may be necessary for other reasons, namely
For iterations the vector is the correction for the global parameter vector in iteration to obtain the global parameter vector for the next iteration.
A method for linear least squares fits with a large number of parameters, perhaps with linear constraints, is discussed in this paper. Sometime of course the model is nonlinear and also constraints may be nonlinear. The standard method to treat these problems is linearization: the nonlinear equation is replaced by a linear equation for the correction of a parameter (Taylor expansion); this requires a good approximate value of the parameter. In principle this method requires an iterative improvement of the parameters, but sometimes even one iteration may be sufficient.
The treatment of nonlinear equations is not directly supported by the program package, but it will in general not be too difficult to organize a program application with nonlinear equations.
Cases with very large residuals within the data can distort the result of the method of least squares. In the method of M-estimates, the least squares method is modified to Maximum likelihood method. Basis is the residual between data and function value (expected data value), normalized by the standard deviation:
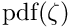
In the method of M-estimates the objective function 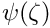 to be minimized is defined in terms of a probability density function of the normalized residual
to be minimized is defined in terms of a probability density function of the normalized residual

From the probability density function 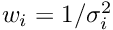 a influence function
a influence function 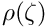 is defined
is defined
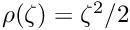
and a weight in addition to the normal least squares weight 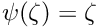 can be derived from the influence function for the calculation of the (modified) normal equations of least squares.
can be derived from the influence function for the calculation of the (modified) normal equations of least squares.
For the standard least squares method the function 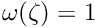 is simply
is simply 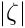 and it follows, that the influence function is
and it follows, that the influence function is 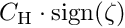 and the weight factor is
and the weight factor is 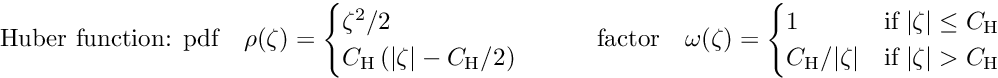 (i.e. no extra weight). The influence function value increases with the value of the normalized residual without limits, and thus outliers have a large and unlimited influence. In order to reduce the influence of outliers, the probability density function has to be modified for large values of
(i.e. no extra weight). The influence function value increases with the value of the normalized residual without limits, and thus outliers have a large and unlimited influence. In order to reduce the influence of outliers, the probability density function has to be modified for large values of 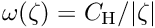 to avoid the unlimited increase of the influence. Several functions are proposed, for example the Huber function and the Cauchy function.
to avoid the unlimited increase of the influence. Several functions are proposed, for example the Huber function and the Cauchy function.
Huber function: A simple function is the Huber function, which is quadratic and thus identical to least squares for small , but linear for larger , where the influence function becomes a constant 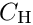 :
:
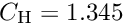
The extra weight is 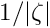 for large . A standard value for
for large . A standard value for 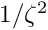 is
is 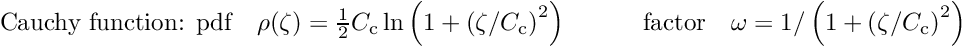 ; for this value the efficiency for Gaussian data without outliers is still 95 %. For very large deviations the additional weight factor decreases with
; for this value the efficiency for Gaussian data without outliers is still 95 %. For very large deviations the additional weight factor decreases with 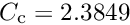 .
.
Cauchy function: For small deviation the Cauchy function is close to the least squares expression, but for large deviations it increases only logarithmically. For very large deviations the additional weight factor decreases with 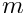 :
:
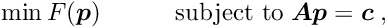
A standard value is 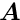 ; for this value the efficiency for Gaussian data without outliers is still 95 %.
; for this value the efficiency for Gaussian data without outliers is still 95 %.
The minimization of an objective function is often not sufficient. Several degrees of freedom may be undefined and require additional conditions, which can be expressed as equality constraints. For 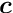 linear equality constraints the problem is the minimization of a non-linear function subject to a set of linear constraints:
linear equality constraints the problem is the minimization of a non-linear function subject to a set of linear constraints:

where 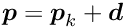 is a -by- matrix and
is a -by- matrix and 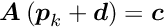 is a -vector with
is a -vector with 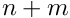 . In iterative methods the parameter vector is expressed by
. In iterative methods the parameter vector is expressed by  with the correction to in the -th iteration, satisfying the equation
with the correction to in the -th iteration, satisfying the equation
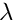
with .
There are two methods for linear constrainst:
parameters are introduced and the linear system of 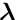 unknowns has to be solved;
unknowns has to be solved;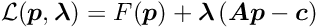 unknowns. However the sparsity of a matrix may be destroyed by the elimination.
unknowns. However the sparsity of a matrix may be destroyed by the elimination.The Lagrange method is used in Millepede.
In the Lagrange multiplier method one additional parameter 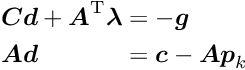 is introduced for each single constraint, resulting in an -vector
is introduced for each single constraint, resulting in an -vector 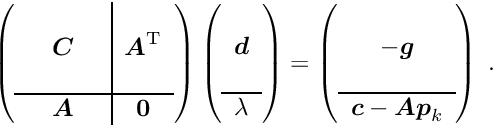 of Lagrange multiplier. A term depending on and the constraints is added to the function , resulting in the Lagrange function
of Lagrange multiplier. A term depending on and the constraints is added to the function , resulting in the Lagrange function
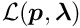
Using as before a quadratic model for the function and taking derivatives w.r.t. the parameters and the Lagrange multipliers , the two equations
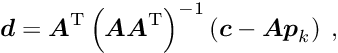
are obtained; the second of these equations is the constraint equation. This system of two equations can be combined into one matrix equation
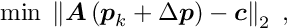
The matrix on the left hand side is still symmetric. Linear least squares problems with linear constraints can be solved directly, without iterations and without the need for initial values of the parameters.
The matrix in equation (10) is indefinite, with positive and negative eigenvalues. A solution can be found even if the submatrix is singular, if the matrix of the constraints supplies sufficient information. Because of the different signs of the eigenvalues the stationary solution is not a minimum of the function  .
.
Feasible parameters. A particular value for the correction can be calculated by
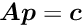
which is the minimum-norm solution of the constraint equation, that is, the solution of
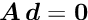
which is zero here. The matrix is a -by- matrix for constraints and the product 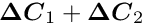 is a square -by- matrix, which has to be inverted in equation (11), which allows to obtain a correction such that the linear constraints are satisfied. Parameter vectors , satisfying the linear constraint equations
is a square -by- matrix, which has to be inverted in equation (11), which allows to obtain a correction such that the linear constraints are satisfied. Parameter vectors , satisfying the linear constraint equations 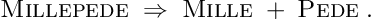 , are called feasible. If the vector in the -th iteration already satisfies the linear constraint equations, then the correction has to have the property
, are called feasible. If the vector in the -th iteration already satisfies the linear constraint equations, then the correction has to have the property 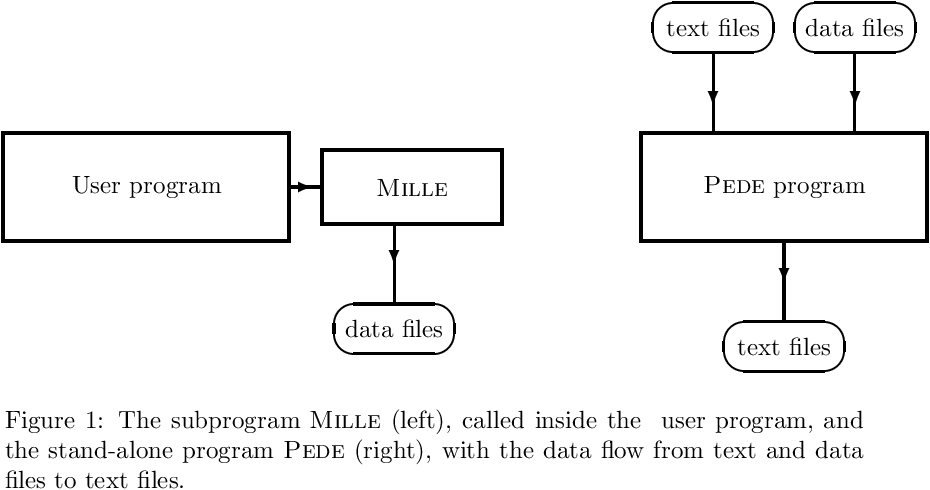 .
.
The second version of the program package with the name Millepede (german: Tausendfüssler) is based on the same mathematical principle as the first version; global parameters are determined in a simultaneous fit of global and local parameters. In the first version the solution of the matrix equation for the global parameter corrections was done by matrix inversion. This method is adequate with respect to memory space and execution time for a number of global parameters of the order of 1000. In actual applications e.g. for the alignment of track detectors at the LHC storage ring at CERN however the number of global parameters is much larger and may be above . Different solution methods are available in the Millepede II version, which should allow the solution of problems with a large number of global parameters with the memory space, available in standard PCs, and with an execution time of hours. The solution methods differ in the requirements of memory space and execution time.
The structure of the second version Millepede II can be visualized as the decay of the single program Millepede into two parts, a part Mille and a part Pede (Figure 1):

The first part, Mille, is a short subroutine, which is called in user programs to write data files for Millepede II. The second part, Pede, is a stand-alone program, which requires data files and text files for the steering of the solution. The result is written to text files.
![\begin{figure}[h] \begin{center} \unitlength1.0cm \begin{picture}(13.0,5.5) \linethickness{0.4mm} \put(0.0,2.0){\framebox(4.0,1.5){User program}} \put(4.5,2.25){\framebox(2.5,1.0){\sc Mille}} \thicklines \put(4.0,2.75){\line(1,0){0.5}} \put(4.0,2.75){\vector(1,0){0.35}} \put(5.5,2.25){\line(0,-1){1.15}} \put(5.5,2.25){\vector(0,-1){0.6}} \put(5.5,0.75){\oval(1.7,0.7)} \put(5.0,0.25){\makebox(1.0,1.0){data files}} \linethickness{0.4mm} \put(9.0,2.0){\framebox(4.0,1.5){{\sc Pede} program}} \thicklines \put(10.0,4.65){\line(0,-1){1.15}} \put(12.0,4.65){\line(0,-1){1.15}} \put(11.0,2.0){\line(0,-1){1.15}} \put(10.0,4.5){\vector(0,-1){0.6}} \put(12.0,4.5){\vector(0,-1){0.6}} \put(11.0,2.0){\vector(0,-1){0.6}} \put(10.0,5.0){\oval(1.7,0.7)} \put(12.0,5.0){\oval(1.7,0.7)} \put(11.0,0.5){\oval(1.7,0.7)} \put(9.5,4.5){\makebox(1.0,1.0){text files}} \put(11.5,4.5){\makebox(1.0,1.0){data files}} \put(10.5,0.0){\makebox(1.0,1.0){text files}} \end{picture} \caption*{Figure 1: The subprogram {\sc Mille} (left), called inside the \label{fig:milped} user program, and the stand-alone program {\sc Pede} (right), with the data flow from text and data files to text files.} \end{center}\end{figure}](form_139.png)
The complete program is on a (tar)-file Mptwo.tgz, which is expanded by the command
tar -xzf Mptwo.tgz
into the actual directory. A Makefile for the program Pede is included; it is invoked by the
make
command. There is a test mode Pede (see section Solution with the stand-alone program Pede), selected by
./pede -t
which can be used to test the program installation.
The computation of the solution for a large number of parameter requires large vector and matrix arrays. Most of the memory space is required in nearly all solution methods for a single matrix. The solution of the corresponding matrix equation is done in-space for almost all methods (no second matrix or matrix copy is needed). The total space of all data arrays, used in Pede, is defined as a dimension parameter within the include file dynal.inc by the statement
PARAMETER (MEGA=100 000 000) ! 100 mio words}
corresponding to the memory space allowed by a 512 Mbyte memory. Larger memories allow an increase of the dimension parameter in this statement in file dynal.inc.
Memory space above 2 Gbyte (?) can not be used with 32-bit systems, but on 64-bit systems; a small change in the makefile to allow linking with a big static array (see file dynal.inc) may be necessary (see comment in makefile).
Data files are written within the user program by the subroutine MILLE, which is available in Fortran and in C. Data on the measurement and on derivatives with respect to local and global parameters are written to a binary file. The file or several files are the input to the stand-alone program Pede, which performs the fits and determines the global parameters. The data required for Millepede and the data collection in the user program are discussed in detail in section Measurements and parameters.
The second part, Pede, is a stand-alone program, which performs the fits and determines the global parameters. It is written in Fortran. Input to Pede are the binary (unformatted) data files, written using subroutine Mille, and text (formatted) files, which supply steering information and, optionally, data about initial values and status of global parameters. Different binary and text files can be combined.
Synopsis:
pede [options] [main steering text file name]
The following options are implemented:
-i interactive mode -t test mode -s subito option: stop after one data loopOption i. The interactive mode allows certain interactive steering, depending on the selected method.
Option t. In the test mode no user input files are required. This mode is recommended to learn about the properties of Millepede. Data files are generated by Monte Carlo simulation for a simple 200-parameter problem, which is subsequently solved. The file generated are: mp2str.txt (steering file), mp2con.txt (constraints) and mp2tst.bin (datafile). The latter file is always (re-)created, the two text files are created, if they do not exit. Thus one can edit these files after a first test job in order to test different methods.
Option s. In the subito mode, the Pede program stops after the first data loop, irrespective of the options selected in the steering text files.
Text files. Text files should have either the characters xt or tx in the 3-character filename-extension. At least one text file is necessary (the default name steer.txt is assumed, if no filename is given in the command line), which specifies at least the names of data files. The text files are described in detail in section Text files.
Pede generates, depending on the selected method, several output text files:
millepede.log ! log-file for pede execution mpgparm.txt ! global parameter results mpdebug.txt ! debug output for selected events mpeigen.txt ! selected eigenvectors
Existing files of the given names are renamed with a 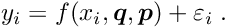 extension, existing files with the extension are removed.
extension, existing files with the extension are removed.
Basic data elements are single measurements ; several single measurements belong to a group of measurements, which can be called a local-fit object. For example in a track-based alignment based on tracks a track is a local-fit object (see section Application: Alignment of tracking detectors for a detailed discussion on the data for tracks in a track-based alignment). A local-fit object is described by a linear or non-linear function 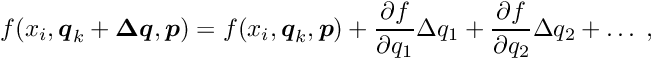 , depending on a (small) number of local parameters and in addition on global parameters :
, depending on a (small) number of local parameters and in addition on global parameters :
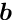
The parameters are called the local parameters, valid for the specific group of measurements (local-fit object). The quantity is the measurement error, expected to have (for ideal parameter values) mean zero (i.e. the measurement is unbiased) and standard deviation ; often will follow at least The quantity is assumed to be the coordinate of the measured value , and is one of the arguments of the function .
The global parameters needed to compute the expectation are usually already quite accurate and only small corrections habe to be determined. The convention is often to define the vector to be a correction with initial values zero. In this case the final values of the global parameters will be small.
The fit of a local-fit object. The local parameters are usually determined in a least squares fit within the users code, assuming fixed global parameter values . If the function depends non-linearly on the local parameters , an iterative procedure is used, where the function is linearized, i.e. the first derivatives of the function with respect to the local parameters are calculated. Then the function is expressed as a linear function of local parameter corrections at some reference value :
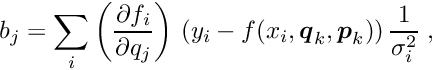
where the derivatives are calculated for . The corrections are determined by the linear least squares method, a new reference value is obtained by
and then, with increased by 1, this is repeated until convergence is reached, i.e. until the corrections become essentially zero. For each iteration a linear system of equations (normal equations of least squares) has to be solved for the parameter corrections with a right-hand side vector 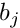 with components
with components
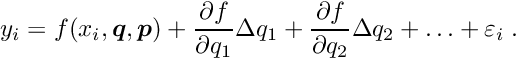
where the sum is over all measurements of the local-fit object. All components 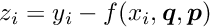 become essential zero after convergence.
become essential zero after convergence.
After convergence the equation (12) can be expressed with the fitted parameters in the form
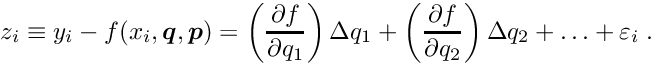
The difference 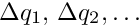 is called the residual and the equation can be expressed in terms of the residual measurement as
is called the residual and the equation can be expressed in terms of the residual measurement as
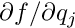
After convergence of the local fit all corrections 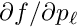 are zero, and the residuals are small and can be called the measurement error. As mentioned above the model function may be a linear or a non-linear function of the local parameters. The fit procedure in the users code may be a more advanced method than least squares. In track fits often Kalman filter algorithms are applied to treat effects like multiple scattering into account. But for any fit procedure the final result will be small residuals , and it should also be possible to define the derivatives
are zero, and the residuals are small and can be called the measurement error. As mentioned above the model function may be a linear or a non-linear function of the local parameters. The fit procedure in the users code may be a more advanced method than least squares. In track fits often Kalman filter algorithms are applied to treat effects like multiple scattering into account. But for any fit procedure the final result will be small residuals , and it should also be possible to define the derivatives 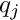 and
and 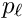 ; these derivatives should express the change of the residual , if the local parameter
; these derivatives should express the change of the residual , if the local parameter 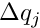 or the global parameter
or the global parameter 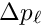 is changed by
is changed by 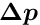 or
or 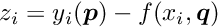 . In a track fit with strong multiple scattering the derivatives will become rather small with increasing track length, because the information content is reduced due to the multiple scattering.
. In a track fit with strong multiple scattering the derivatives will become rather small with increasing track length, because the information content is reduced due to the multiple scattering.
Local fits are later (in Pede) repeated in a simplified form; these fits need as information the difference and the derivatives, and correspond to the last iteration of the local fit, because only small parameter changes ares involved. Modified values of global parameters during the global fit result in a change of the value of and therefore of , which can be calculated from the derivatives. The derivatives with respect to the local parameters allow to repeat the local fit and to calculate corrections for the local parameters .
Now the global parameters are considered. The calculation of the residuals depends on the global parameters (valid for all local-fit objects). This dependence can be considered in two ways. As expressed above, the parametrization depends on the global parameters and on corrections 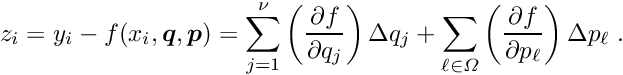 of the global parameters (this case is assumed below in the sign of the derivatives with respect to the global parameters). Technically equivalent is the case, where the measured value is calculated from a raw measured value, using global parameter values; in this case the residual could be written in the form
of the global parameters (this case is assumed below in the sign of the derivatives with respect to the global parameters). Technically equivalent is the case, where the measured value is calculated from a raw measured value, using global parameter values; in this case the residual could be written in the form 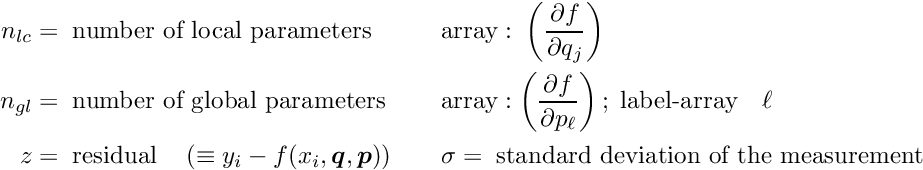 . It is assumed that reasonable values are already assigned to the global parameters and the task is to find (small) corrections to these initial values.
. It is assumed that reasonable values are already assigned to the global parameters and the task is to find (small) corrections to these initial values.
Equation (13) is extended to include corrections for global parameters. Usually only few of the global parameters influence a local-fit object. A global parameter carries a label , which is used to identify the global parameter uniquely, and is an arbitrary positive integer. Assuming that labels from a set contribute to a single measurement the extended equation becomes

Millepede essentially performs a fit to all single measurements for all groups of measurements simultaneously for all sets of local parameters and for all global parameters. The result of this simultaneous fit are optimal corrections for all global parameters; there are no limitations in the number of local parameters sets. Within this global fit the local fits (or better: the last iteration of the local fit) has to be repeated for each local-fit object.
Global parameter labels. The label , carried by a global parameter, is an arbitrary positive (31-bit) integer (most-significant bit is zero), and is used to identify the global parameter uniquely. Arbitrary gaps between the numerical values of labels values are allowed. It is recommended to design the label in a way which allows to reconstruct the meaning of the global parameter from the numerical value of the label .
The user has to provide the following data for each single measurement:
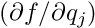
These data are sufficient to compute the least squares normal equations for the local and global fits. Using calls of MILLE the measured data and the derivatives with respect to the local and global parameters are specified; they are collected in a buffer and written as one record when one local-fit object is finished in the user reconstruction code.
Calls for Fortran version: Data files should be written with the Fortran MILLE on the system used for Pede; otherwise the internal file format could be different.
CALL MILLE(NLC,DERLC,NGL,DERGL,LABEL,RMEAS,SIGMA)
where
NLC 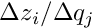 number of local parameters
number of local parameters DERLC DERLC array DERLC(NLC) of derivativesNGL number of global derivatives in this callDERGL array DERLG(NGL) of derivativesLABEL array LABEL(NGL) of labelsRMEAS measured valueSIGMA error of measured value (standard deviation)After transmitting the data for all measured points the record containing the data for one local-fit object is written. following call
CALL ENDLE
The buffer content is written to a file with the record.
Alternatively the collected data for the local-fit object have to be discarded, if some reason for not using this local-fit object is found.
CALL KILLE
The content of the buffer is reset, i.e. the data from preceeding MILLE calls are removed.
Additional floating-point and integer data (special data) can be added to a local fit object by the call
CALL MILLSP(NSPEC,FSPEC,ISPEC)
where
NSPEC number of special data DERLC FSPEC array FSPEC(NSPEC) of floating point dataISPEC array ISPEC(NSPEC) of integer dataThe floating-point and integer arrays have the same length. These special data are not yet used, but may be used in future options.
Calls for C version: The C++-class Mille can be used to write C-binary files. The constructor
Mille(const char *outFileName, bool asBinary = true, bool writeZero = false);
takes at least one argument, defining the name of the output file. For debugging purposes it is possible to give two further arguments: If asBinary is false, a text file (not readable by pede) is written instead of a binary output. If writeZero is true, derivatives that are zero are not suppressed in the output as usual.
The member functions
void mille(int NLC, const float *derLc, int NGL, const float *derGl,
const int *label, float rMeas, float sigma);
void special();
void end();
void kill(); have to be called equivalently like the Fortran subroutines MILLE, MILLSP, ENDLE} and KILLE. To properly close the output file, the Mille object should be deleted (or go out of scope) after the last processed record.
Root version: A root version is perhaps added in the future.
Experience has shown that non-linearities in the function are usually small or at least not-dominating. As mentioned before, the convention is often to define the start values of the global parameters as zero and to expect only small final values. Derivatives with respect to the local and global parameters can be assumed to be constants within the range of corrections in the determination of the global parameter corrections. Then a single pass through the data, writing data files and calculating global parameter corrections with Millepede is sufficient. If however corrections are large, they may require to re-calculate the derivatives and another pass or several passes through the data with re-writing data files may be necessary. As a check of the whole procedure a second pass is recommended.
In the alignment of tracking detectors the group of measurement, the local-fit object, may be the set of hits belonging to a single track. Two to five parameters may be needed to describe the dependence of the measured values on the coordinate .
In a real detector the trajectory of a charged particle does not follow a simple parametrization because of effects like multiple scattering due to the detector material. In practice often a Kalman filter method is used without an explicit parametrization; instead the calculation proceeds along the track taking into account e.g. multiple scattering effects. Derivatives with respect to the (local) track parameters are not directly available. Nevertheless derivatives as required in equation (14) are still well-defined and can be calculated. Assuming that the (local) track parameters refer to the starting point of the track, for each point along the track the derivative 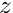 has to be equal to
has to be equal to 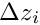 , if the local parameter if changed by , and the corresponding change of the residual
, if the local parameter if changed by , and the corresponding change of the residual 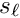 is
is 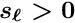 . This derivative could be calculated numerically.
. This derivative could be calculated numerically.
For low-momentum tracks the multiple-scattering effects are large. Thus the derivative above will tend to small values for measured points with a lot of material between the measured point and the starting point of the track. This shows that the contribution of low-momentum tracks with large multiple-scattering effects to the precision of an alignment is small.
In text files the steering information for the program execution and further information on parameters and constraints is given. The main text file is mandatory. Its default name is steer.txt; if the name is different it has to be given in the command line of Pede. In the main text file the file names of data files and optionally of further text files are given. Text files should have an extension which contains the character pairs xt or tx. In this section all options for the global fits and their keywords are explained. The computation of the global fit is described in detail in the next section Computation of the global fit; it may be necessary to read this section Computation of the global fit to get an understanding of the various options.
Text files contain file names, numerical data, keywords (text) and comment in free format, but there are certain rules.
File names for all text and steering file should be the leading information in the main steering file, with one file name per line, with correct characters, since the file names are used to open the files.
Numerical can be given with or without decimal point, optionally with exponent field. The numerical data
13234 13234.0 13.234E+3
are all identical.
Comments can be given in every line, preceeded by the ! sign; the text after the ! is ignored. Lines with * or ! in the first columm are considered as comment lines. Blank lines are ignored.
Keywords are necessary for certain data; they can be given in upper or lower case characters. Keywords with few typo errors may also be recognized correctly. The program will stop if a keyword is not recognized.
Below is an example for a steering file:
Fortranfiles !/home/albert/filealign/lhcrun1.11 ! data from first test run /home/albert/filealign/lhcrun2.11 ! data from second run /home/albert/filealign/cosmics.bin ! cosmics /home/albert/detalign/mydetector.txt ! steering file from previous log file /home/albert/detalign/myconstr.txt ! test constraints constraint 0.14 ! numerical value of r 713 1.0 ! pair of parameter label and numerical factor 719 0.5 720 0.5 ! two pairs CONSTRAINTS 1.2 112 1.0 113 -1.0 114 0.5 116 -0.5 Parameter 201 0.0 -1.0 202 1.0 -1.0 204 1.23 0.020 method inversion 5 0.1 end
Names of data and text files are given in single text lines. The file-name extension is used to distinguish text files (extension containing tx or xt) and binary data files. Data files may be Fortran or C files; by default C files are assumed. Fortran files have to be preceded by the textline
Fortranfiles
and C files may be preceded by the textline
Cfiles
Mixing of C- and Fortran-files is allowed.
By default all global parameters appearing in data files with their labels are assumed to be variable parameters with initial value zero, and used in the fit. Initial values different from zero and the so-called presigma (see below) may be assigned to global parameters, identified by the parameter label. The optional parameter information has to be provided in the form below, starting with a line with the keyword Parameter:
Parameter
label initial_value presigma
...
label initial_value presigma
The three numbers label, initial_value and presigma in a textline may be followed by further numbers, which are ignored.
All parameters not given in this file, but present in the data files are assumed to be variable, with initial value of zero.
Pre-sigma. The pre-sigma 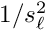 defines the status of the global parameter:
defines the status of the global parameter:
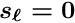 : The parameter is variable with the given initial value. A term
: The parameter is variable with the given initial value. A term  is added to the diagonal matrix element of the global parameter to stabilize a perhaps poorly defined parameter. This addition should not bias the fitted parameter value, if a sufficient number of iterations is performed; it may however bias the calculated error of the parameter (this is available only for the matrix inversion method).
is added to the diagonal matrix element of the global parameter to stabilize a perhaps poorly defined parameter. This addition should not bias the fitted parameter value, if a sufficient number of iterations is performed; it may however bias the calculated error of the parameter (this is available only for the matrix inversion method).
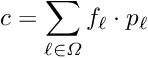 : The pre-sigma is zero; the parameter is variable with the given initial value.
: The pre-sigma is zero; the parameter is variable with the given initial value.
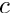 : The pre-sigma is negative. The parameter is defined as fixed; the initial value of the parameter is used in the fits.
: The pre-sigma is negative. The parameter is defined as fixed; the initial value of the parameter is used in the fits.
The lines below show examples, with the numerical value of the label, the initial value, and the pre-sigma:
11 0.01232 0.0 ! parameter variable, non-zero initial value 12 0.0 0.0 ! parameter variable, initial value zero 20 0.00232 0.0300 ! parameter variable with initial value 0.00232 30 0.00111 -1.0 ! parameter fixed, but non-zero parameter value
Result file. At the end of the Pede program a result file millepede.res with the result is written. In the first three columns it carries the label, the fitted parameter value (initial value + correction) and the pre-sigma (default is zero). This file can, perhaps after editing, be used for a repeated Pede job. Column 4 contains the correction and in the case of solution by inversion or diagonalization column 5 its error and optionally column 6 the global correlation.
Equality constraints allow to fix certain undefined or weakly defined linear combinations of global parameters by the addition of equations of the form
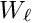
The constraint value 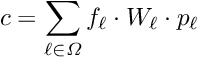 is usually zero. The format is:
is usually zero. The format is:
Constraint value
label factor
...
label factor
where value, label and factor are numerical values. Note that no error of the value is given. The equality constraints are, within the numerical accuracy, exactly observed in a global fit. Each constraint adds another Lagrange multiplier to the problem, and needs the corresponding memory space in the matrix.
Instead of the keyword Constraint the keyword Wconstraint can be given (this option is not yet implemented!). In this case the factor for each global parameter given in the text file is, in addition, multiplied by the weight 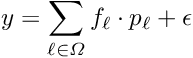 of the corresponding global parameter in the complete fit:
of the corresponding global parameter in the complete fit:
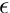
Thus global parameters with a large weight in the fit get also a large weight in the constraint.
Mathematically the effect of a constraint does not change, if the constraint equation is multiplied by an arbitrary number. Because of round-off errors however it is recommended to have the constraint equation on a equal accuracy level, perhaps by a scale factor for constraint equations.
Measurements with measurement value and measurement error for linear combinations of global parameters in the form
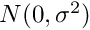
can be given, where 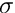 is the measurement error, assumed to follow a distribution
is the measurement error, assumed to follow a distribution  , i.e. zero bias and standard deviation
, i.e. zero bias and standard deviation 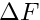 . The format is:
. The format is:
Measurement value sigma
label factor
...
label factor
where value, sigma, label and factor are numerical values. Each measurement value  sigma (standard deviation) given in the text files contributes to the overall objective function in the global fit. At present no outlier tests are made.
sigma (standard deviation) given in the text files contributes to the overall objective function in the global fit. At present no outlier tests are made.
The global parameter measurement and the constraint information from the previous section differ, in the definition, only in the additional information on the standard deviation given for the measurement. They differ however in the mathematical method: constraints add another parameter (Lagrange multiplier); measurements contribute to the parameter part of the matrix, and may require no extra space; however a sparse matrix may become less sparse, if matrix elements are added, which are empty otherwise.
Methods. One out of several solution methods can be selected. The methods have different execution time and memory space requirement, and may also have a slighly different accuracy. The statement to select a method are:
method inversion number1 number2 method diagonalization number1 number2 method fullGMRES number1 number2 method sparseGMRES number1 number2 method cholesky number1 number2 method bandcholesky number1 number2 method HIP number1 number2
The two numbers are:
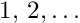 (convergence recognition).
(convergence recognition).For preconditioning in the GMRES methods a band matrix is used. The width of the variable-band matrix is defined by
bandwidth number
where number is the numerical value of the semi-bandwidth of a band matrix. The method called bandcholesky uses only the band matrix (reduced memory space requirement), and needs more iterations. The different methods are described below.
Iterations and convergence. The mathematical method in principle allows to solve the problem in a single step. However due to potential inaccuracies in the solution of the large linear system and due to a required outlier treatment certain internal iterations may be necessary. Thus the methods work in iterations, and each iteration requires one or several loops with evaluation of the objective function and the first-derivative vector of the objective function (gradient), which requires reading all data and local fits of the data. The first loop is called iteration 0, and (only) in this loop in addition the second-derivative matrix is evaluated, which takes more cpu time. This first loop usually brings a large reduction of the value of the objective function, and all following loops will bring small additional improvements. In all following loops the same second-derivative matrix is used (in order to reduce cpu time), which should be a good approximation.
A single loop may be sufficient, if there are no outlier problems. Using the command line option 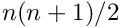 (subito) the program executes only a single loop, irrespective of the options required in the text files. The treatment of outliers turns a linear problem into a non-linear problem and this requires iterations. Also precision problems, with rounding errors in the case of a large number of global parameters, may require iterations. Each iteration
(subito) the program executes only a single loop, irrespective of the options required in the text files. The treatment of outliers turns a linear problem into a non-linear problem and this requires iterations. Also precision problems, with rounding errors in the case of a large number of global parameters, may require iterations. Each iteration 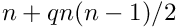 is a line search along the calculated search direction, using the strong Wolfe conditions, which force a sufficient decrease of the function value and the gradient. Often an iteration requires only one loop. If, in the outlier treatment, a cut is changed, or if the precision of the constraints is insufficient, one additional loop may be necessary.
is a line search along the calculated search direction, using the strong Wolfe conditions, which force a sufficient decrease of the function value and the gradient. Often an iteration requires only one loop. If, in the outlier treatment, a cut is changed, or if the precision of the constraints is insufficient, one additional loop may be necessary.
At present the iterations end, when the number specified with the method is reached. For each loop, the expected objective-function decrease and the actual decrease are compared. If the two values are below the limit for specified with the method, the program will end earlier.
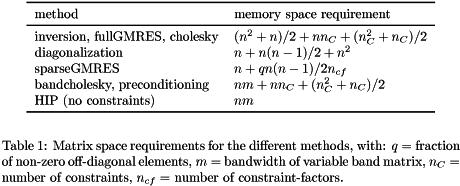
Memory space requirements. The most important consumer of space is the symmetric matrix of the normal equations. This matrix has a parameter part, which requires for example for full storage 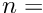 words, and for sparse storage
words, and for sparse storage 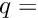 words, for
words, for  number of global parameters and
number of global parameters and 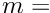 fraction of non-zero off-diagonal elements. In addition the matrix has a constraint part, corresponding to the Lagrange multipliers. Formulae to calculate the number of (double precision) elements of the matrix are given in table 1.
fraction of non-zero off-diagonal elements. In addition the matrix has a constraint part, corresponding to the Lagrange multipliers. Formulae to calculate the number of (double precision) elements of the matrix are given in table 1.
The GMRES method can be used with a full or with a sparse matrix. Without preconditioning the GMRES method may be slow or may even fail to get an acceptable solution. Preconditioning is recommended and usually speeds up the GMRES method considerably. The band matrix required for preconditioning also takes memory space. The parameter part requires (only) 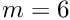 words, where
words, where 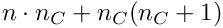 semibandwidth specified with the method. A small value like
semibandwidth specified with the method. A small value like 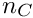 is usually sufficient. The constraint part of the band matrix however requires up to
is usually sufficient. The constraint part of the band matrix however requires up to 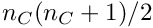 words, and this can be a large number for large number
words, and this can be a large number for large number 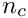 of constraint equations.
of constraint equations.
Another matrix with 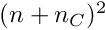 words is required for the constraints, and this matrix is used to improve the precision of the constraints. Several vectors of length and are used in addition, but this space is only proportional to and
words is required for the constraints, and this matrix is used to improve the precision of the constraints. Several vectors of length and are used in addition, but this space is only proportional to and 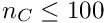 .
.
The diagonalization method requires more space: in addition to the symmetric matrix another matrix with 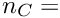 words is used for the eigenvectors; since diagonalization is also slower, the method can only be used for smaller problems.
words is used for the eigenvectors; since diagonalization is also slower, the method can only be used for smaller problems.
Comparison of the methods. The methods have a different computing-time dependence on the number of parameters . The methods diagonalization, inversion and cholesky have a computing time proportional to the third power of n, and can therefore be used only up to 1000 or perhaps up to 5000. Especially the diagonalization is slow, but provides a detailed information on weakly- and well-defined linear combinations of global parameters.
The GMRES methods has a weaker dependence on , and allows much larger -values; larger values of of course require a lot of space and the sparse matrix mode should be used. The bandcholesky method can be used for preconditioning the GMRES method (recommended), but also as a stand-alone method; its cpu time depends only linearly on , but the matrix is only an approximation and usually many iterations are required. For all methods the constraints increase the time and space consumption; this remains modest if the number of constraints is modest, for example 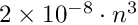 , but may be large for
, but may be large for 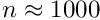 several thousand.
several thousand.
Inversion. The computing time for inversion is roughly 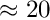 seconds (on a standard PC). For
seconds (on a standard PC). For 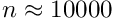 the inversion time of
the inversion time of 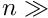 seconds is still acceptable, but for
seconds is still acceptable, but for 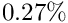 the inversion time would be already more than 5 hours. The advantage of the inversion is the availability of all parameter errors and global correlations.
the inversion time would be already more than 5 hours. The advantage of the inversion is the availability of all parameter errors and global correlations.
Cholesky decomposition. The Cholesky decomposition (under test) is an alternative to inversion; eventually this method is faster and/or numerically more stable than inversion. At present parameter errors and global correlations are not available.
Diagonalization. The computing time for diagonalization is roughly a factor 10 larger than for inversion. Space for the square (non-symmetric) transformation matrix of eigenvectors is necessary. Parameter errors and global correlations are calculated for all parameters. The main advantage of the diagonalization method is the availability of the eigenvalues. Small positive eigenvalues of the matrix correspond to linear combinations of parameters which are only weakly defined and it will become possible to interactively remove the weakly defined linear combinations. This removal could be an alternative to certain constraints. Constraints are also possible and they should correspond to negative eigenvalues.
Generalized minimization of residuals (GMRES). The GMRES method is a fast iterative solution method for full and sparse matrices. Especially for large dimensions with 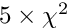 1000 it should be much faster than inversion, but of similar accuracy. Although the solution is fast, the building of the sparse matrix may require a larger cpu time. At present there is a limit for the number of internal GMRES-iterations of 2000. For a matrix with a bad condition number this number of 2000 internal GMRES-iterations will often be reached and this is often also an indication of a bad and probably inaccurate solution. An improvement is possible by preconditioning, selected if GMRES is selected together with a bandwidth parameter for a band matrix; an approximate solution is determined by solving the matrix equation with a band matrix within the GMRES method, which improves the eigenvalue spectrum of the matrix and often speeds up the method considerably. Experience shows that a small bandwidth of e.g. 6 is sufficient. In interactive mode parameter errors for selected parameters can be determined.
1000 it should be much faster than inversion, but of similar accuracy. Although the solution is fast, the building of the sparse matrix may require a larger cpu time. At present there is a limit for the number of internal GMRES-iterations of 2000. For a matrix with a bad condition number this number of 2000 internal GMRES-iterations will often be reached and this is often also an indication of a bad and probably inaccurate solution. An improvement is possible by preconditioning, selected if GMRES is selected together with a bandwidth parameter for a band matrix; an approximate solution is determined by solving the matrix equation with a band matrix within the GMRES method, which improves the eigenvalue spectrum of the matrix and often speeds up the method considerably. Experience shows that a small bandwidth of e.g. 6 is sufficient. In interactive mode parameter errors for selected parameters can be determined.
Variable band matrix. Systems of equations with a band matrix can be solved by the Cholesky decomposition. Often the matrix element around the diagonal are the essential matrix elements and in these cases the matrix can be approximated by a band matrix of small width, with a small memory requirement. The computing time is also small; it is linear with the number of parameters. However because the band matrix is only the approximate matrix often many iterations are necessary to get a good solution. The definition of the band width is necessary. The band width is variable and thus the constraints equations can be treated completely. This means that the constraints are observed even in this approximate solution.
Cases with very large residuals within the data can distort the result of the least squares fit. Reason for outliers may be selection mistakes or statistical fluctuations. A good outlier treatment may be neccessary to get accurate results. The problem of outlier treatment is complicated by the fact that initially the global parameters may be far from optimal and therefore large deviation may occur even for correct data before the global parameter determination. There are options for the complete removal of bad cases and for the down-weighting of bad data. Cases with a huge are automatically removed in every iteration. The options to remove large cases and down-weighting are not done in the first iteration. The options are:
chisqcut number1 number2 outlierdownweighting number dwfractioncut number printrecord number1 number2
Chisquare cut. With the keyword chisqcut two numbers can be given. Basis of rejection is the -value corresponding to 3 standard deviations (and to a probability of 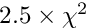 ). or one degree of freedom this -value is 9.0, and for 10 degrees of freedom the -value is 26.9. The first number given with the keyword
). or one degree of freedom this -value is 9.0, and for 10 degrees of freedom the -value is 26.9. The first number given with the keyword chisqcut is a factor for the -cut value, to be used in the first iteration, and the second number is the factor for the second iteration. In subsequent iterations the factor is reduced by the square root, with values below 1.5 replaced by 1. For example the statement
chisqcut 5.0 2.5
means: the cut factor is 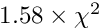 -value corresponding to three standard deviations,
-value corresponding to three standard deviations, 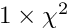 -value for the second iteration,
-value for the second iteration, 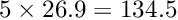 -value for the third iteration and
-value for the third iteration and 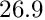 -value for subsequent iterations. Thus in the first iteration the cut is
-value for subsequent iterations. Thus in the first iteration the cut is 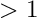 for 10 degrees of freedom, and
for 10 degrees of freedom, and 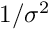 after the third iteration.
after the third iteration.
Outlier downweighting. Outlier down-weighting for single data values requires repeated local fits with 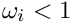 iterations in the local fit. The number given with the keyword
iterations in the local fit. The number given with the keyword outlierdownweighting is the number of iterations. In down-weighting the weight of the data point, which by default is 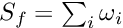 , is reduced by an extra factor
, is reduced by an extra factor 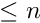 according to the residual (see below). For data points the total sum
according to the residual (see below). For data points the total sum 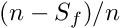 of the extra factors is
of the extra factors is 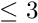 . The ratio
. The ratio 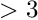 is called the down-weight fraction, and a histogram of this ratio is accumulated in the second function evaluation. The first iteration of the local fit is done without down-weighting, iterations 2 and 3 use the M-estimation method with the Huber function. Subsequent iterations, if requested, use the M-estimation method with the Cauchy function for down-weighting, where the influence of very large deviations is further reduced. For example the statement
is called the down-weight fraction, and a histogram of this ratio is accumulated in the second function evaluation. The first iteration of the local fit is done without down-weighting, iterations 2 and 3 use the M-estimation method with the Huber function. Subsequent iterations, if requested, use the M-estimation method with the Cauchy function for down-weighting, where the influence of very large deviations is further reduced. For example the statement
outlierdownweighting 4
means: iteration 1 of the local fit without down-weighting, iterations 2 and 3 with Huber function down-weighting and iteration 4 with Cauchy function down-weighting.
Downweighting fraction cut. Cases with a very large fraction of down-weighted measurements are very likely wrong data and should be rejected. The cut value should be determined from the histogram showing the down-weight fraction. Typical values are 0.1 for weights from the Huber function (outlierdownweighting 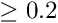 ) and 0.2 for weights from the Cauchy function (
) and 0.2 for weights from the Cauchy function (outlierdownweighting 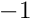 ). For example the statement
). For example the statement
dwfractioncut 0.2
means to reject all cases with a down-weight fraction 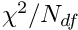 .
.
Record printout. For debugging many details of single records and the local fits are printed. Two record number number1 number2 can be given with the keyword printrecord; printout is done in iteration 1 and 3. For numbers given as negative, the records with extreme deviations are selected in iteration 2, and printed in iteration 3. If the first number is given as 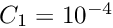 , the record with the largest single residual is selected. If the second number is given as , the record with the largest value of
, the record with the largest single residual is selected. If the second number is given as , the record with the largest value of 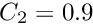 is selected. For example the statement
is selected. For example the statement
printrecord 4321 -1
means: the record 4321 is printed in iterations 1 and 3, and the record with the largest value of is selected in iteration 2 and printed in iteration 3.
There are miscellaneous further options which can be selected within the text files:
subito entries number nofeasiblestart wolfe C1 C2 histprint end
The option subito is also selected by -s in the command line. The program will end regularly, with normal output of the result, already after the first function evaluation (iteration 0).
The number, given with the keyword entries, is the minimum number of data for a global parameter. Global parameters which have a number of entries number of measured points connected to it in the local fit-objects, smaller then the given number are ignored. This option is used to suppress global parameters with only few data, which are therefore rather inaccurate, and would spoil the condition of the linear system.
By default the initial global parameter values are corrected to follow all the constraints. A check for the validity of the constraints is repeated in every iteration, and eventually another correction is made at the end of an iteration. With the keyword nofeasiblestart the parameters are not made feasible (respecting the constraints) at the start.
The constants C1 and C2 are the line search constants for the strong Wolfe conditions; default values are the standard values 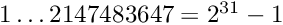 and
and  .
.
Histograms accumulated during the program are written to the textfile millepede.his and can be read after the job execution. If selected by the keyword histprint the histograms accumulated during the program are also printed.
The reading of a textfile ends, when the keyword end is encountered. Textlines after the line with end are not read.
The solution of the optimization problem for a large number of parameters requires one large memory with many arrays, required to store vectors and matrices of large size corresponding to the number of parameters and constraints. Millepede II uses a large array in a common. This large array is dynamically divided into so-called subarrays, which are created, enlarged and moved, and removed according to the requirements. The space limitation is thus given for almost all subproblems only by the total space requirement. The largest space is required for the symmetric matrix of the normal least squares equations. This matrix can be a full matrix or for certain problems a sparse matrix. As an approximation a band matrix with a small band width can be used, if there is not enough space for the full or sparse matrix.
After initialization of the memory management the command line options are read and analysed. Then the main text file is analysed, the names of other text files and the data files are recognized and stored in a table. Default value are assigned to the various variables; then all text files are read and the requested options are interpreted. The data for the definition for parameters, constraints and measurement are read and stored in subarrays.
In subroutine LOOP1 tables for the variable and fixed global parameters and translation tables are defined. The table of global parameter labels is first filled with the global parameters, appearing in the text files. All data files are read and all global parameter labels from the records are included in the list.
There are three integers to characterize a global parameter.
Global parameter label = ITGBL: this is a positive integer, from the full range of 32-bit integers.  .
.
Global parameter index = ITGBL: A translation table is constructed to translate the global parameter label ITGBL to a global parameter index ITGBI, with a range 
NTGB, where NTGB is the total number of global parameters (variable and fixed parameters).
Variable-parameter index = IVGBI: the global parameters which are variable carry a variable-parameter index, with a range NVGB, where NVGB is the number of variable global parameters. Parameter vectors in the mathematical computation are vectors containing only the variable parameters.
Function calls are used to translate the global parameter label ITGBL:
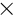
The translation is done with a hash-index table. The translation from one parameter index to another one and back to the parameter label is done by the following statement functions:
which use simple fixed-length tables.
In subroutine LOOP2 the subarray dimensions of the various vectors and matrices are determined. All data files are read and for each local-fit object the number of local and of global parameters is determined; the maximum values of the numbers are used to define the subarray dimensions for the arrays to be used in local fits, and for the contributions to the global fit.
The sparse matrix storage requires to establish the pointer structure of the sparse matrix. During reading the data files the list of global parameters used in each local-fit object is determined; an entry is made in a table for each pair of global parameters, which later corresponds to an off-diagonal matrix element. A hash-index table is used for the search operation. For sparse and full matrix storage the requirements of the constraint equations and Lagrange multipliers has to be included. For the sparse matrix a pointer structure is build, which allows a fast matrix 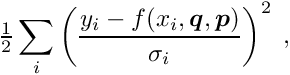 *vector* product. At the end of the subroutine all subarrays required for the determination of the solution are prepared.
*vector* product. At the end of the subroutine all subarrays required for the determination of the solution are prepared.
The section gives an short overview over the solution method; more detailed explanation is given in the subsequent sections.
In principle the solution can be determined in a single step; this mode can be selected by the keyword subito or option -s. There are however two reasons to perform iterations, which improve the result:
The solution determined in iterations is explained. The starting iteration, with iteration number 0, is the most important and time-consuming one. The data files are read, and for each case a local fit is made. The matrix of the normal equations is formed only in this starting iteration. Depending on the selected method the matrix is inverted, diagonalized or decomposed, and the resulting matrix and decomposition is used in all later data-file loops, which take less time compared to the first data-file loop. Thus the data-file loop in iteration number 0 may be rather time consuming, especially for the case of a sparse matrix, where the index determination takes some time. The right-hand-side vector is formed in each data-file loop. A correction step in global parameter space is calculated at the end of the data-file loop in iteration number 0. Often the precision is already sufficient and no further data-file loops are necessary. In the subito mode (keyword subito or option -s) the correction is added to the global parameter values and the program stops.
Iterations with more data-file loops are recommended, to check the result, eventually to improve the result and to treat outliers. In each iterations a so-called line search is done, where the overall value of the objective functions is optimized along the correction-step direction sufficiently, using the strong Wolfe criterion. Often a single step is already sufficient for an iteration. The sample of local-fit objects may change during the iterations becuse of changing cut values; this may require extra function and derivative calculations.
In subroutine LOOPN all data files are read. For each local-fit object the local fit is performed, based on the actual global parameter corrections, and eventually including downweighting of outliers. Using the results of the local fit the value of the objective function 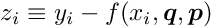 , the vector of first derivatives (gradient) and, in the first data file loop, the matrix of second derivatives is calculated. For a linear fit the matrix of second derivatives will not change during the iterations; the outlier treatment will change the matrix, but usually the changes are small und the matrix collected in the first data loop is at least a good and sufficiently accurate approximation. Thus data loops after the first one are faster; depending on the method the solution of the matrix equation will be faster after the first data loop.
, the vector of first derivatives (gradient) and, in the first data file loop, the matrix of second derivatives is calculated. For a linear fit the matrix of second derivatives will not change during the iterations; the outlier treatment will change the matrix, but usually the changes are small und the matrix collected in the first data loop is at least a good and sufficiently accurate approximation. Thus data loops after the first one are faster; depending on the method the solution of the matrix equation will be faster after the first data loop.
The number of local parameters of a local-fit object is usually small; typical values are between 2 and 5. Since the problem is linear, a single step is sufficient in a local fit with minimization of the sum
unless outlier downweighting is required, which may require a few iterations. In a loop over the local measurements the matrix and the right-hand side of the least squares normal equations are summed. For each single measured value, the residual measurement
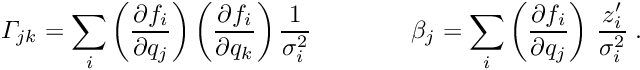
(see equation (13)) has to be corrected for the actual global parameters corrections using the first global parameter derivatives (see equation (14)). The corrected residual 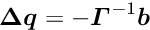 is then used in the accumulation of the matrix and vector:
is then used in the accumulation of the matrix and vector:
Corrections are determined by the solution of the matrix equation
which is determined using matrix inversion 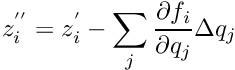 , because the inverse matrix
, because the inverse matrix  (the covariance matrix) is necessary for the contribution to the matrix of the global normal equations. The residual are then corrected for the local parameter corrections:
(the covariance matrix) is necessary for the contribution to the matrix of the global normal equations. The residual are then corrected for the local parameter corrections:
and the new residuals 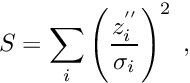 are used to calculate the value
are used to calculate the value  of the local fit
of the local fit
which should follow a . The number of local parameters of a local-fit object is usually small; typical values are between 2 and 5. Since the problem is linear, a single step is sufficient in a local fit with minimization of the sum
unless outlier downweighting is required, which may require a few iterations. In a loop over the local measurements the matrix and the right-hand side of the least squares normal equations are summed. For each single measured distribution with the given number of degrees of freedom  number of measurements minus number of parameters. A fraction of 0.27 % or one out of 370 of the correct cases should have a deviation which corresponds to 3 standard devations in the
number of measurements minus number of parameters. A fraction of 0.27 % or one out of 370 of the correct cases should have a deviation which corresponds to 3 standard devations in the  case.
case.
Very badly fitting cases should be rejected before using them for the global parameter fit. Basis of the rejection is the comparison of the sum and the 0.27 % value  of the
of the 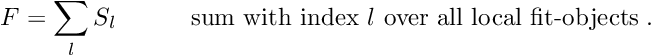 distribution. If the value exceeds by more than a factor of 50, then the sum is called huge and the local-fit object is rejected. Cases with
distribution. If the value exceeds by more than a factor of 50, then the sum is called huge and the local-fit object is rejected. Cases with 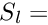 are rejected too, because they do no allow any check. These rejections are always made, even if the user has not requested any outlier rejection.
are rejected too, because they do no allow any check. These rejections are always made, even if the user has not requested any outlier rejection.
With keyword chisqcut the user can require a further rejection. The first number given with the keyword is used during iteration 0; the local-fit object is rejected, if the value is larger than this number times . Often this number has to rather high, e.g. 12.0; the initial value of may be rather high before the first determination of global parameters, even for correct data, and, if possible, no correct data should be rejected by the cut. The second number given with the keyword is used during iteration 1 and can be smaller than the first number, because the first improvement of the local parameters is large. In further iterations the number is reduced by the sqrt-function. Values below 1.5 are replaced by 1, and thus the rejection is finally be done with a 0.27 %-rejection probability for correct data.
All not rejected local-fit objects contribute to the global fit. The function value is the sum of the -values for the local-fit objects:
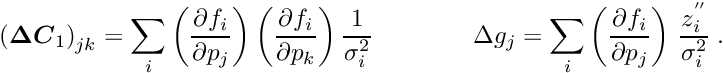
Here even -values from local-fit objects, which are rejected by cuts are included, with  cut value, in order to keep the sum meaningful (otherwise the rejection of many local-fit object could simulate an improvement – which is not the case).
cut value, in order to keep the sum meaningful (otherwise the rejection of many local-fit object could simulate an improvement – which is not the case).
After an accepted local fit the contributions to the normal least squares equations of the global fit have to be calculated. The first contribution is from the first order derivatives with respect to the global parameters:
Note that in the 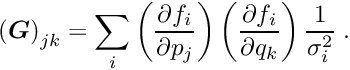 -term the residual is already corrected for the local fit result. The vector is the gradient of the global objective function.
-term the residual is already corrected for the local fit result. The vector is the gradient of the global objective function.
The second contribution is, according to the Millepede principle, a mixed contribution from first order global and local derivatives. After the local fit the matrix 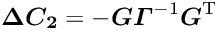 is formed, which has a number of columns equal to the number of local parameters, and a number of rows equal to the number of global parameters. The elements are
is formed, which has a number of columns equal to the number of local parameters, and a number of rows equal to the number of global parameters. The elements are
The second contribution to the global matrix is then
with the matrices and from a local fit. Because of the dimension of matrices and 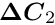 the calculation would require a large number of operations. However only a small number of rows of matrix is not equal to zero and the calculation can be restricted, with the help of pointers, to the non-zero part and in addition one can use the fact that the result is a symmetric matrix. With this code, which may appear somewhat complicated in comparison to the standard matrix multiplication, the computation time is small. Note that no extra contribution to the gradient vector is necessary because the residual used above already includes the local fit result. The sum of the two contributions,
the calculation would require a large number of operations. However only a small number of rows of matrix is not equal to zero and the calculation can be restricted, with the help of pointers, to the non-zero part and in addition one can use the fact that the result is a symmetric matrix. With this code, which may appear somewhat complicated in comparison to the standard matrix multiplication, the computation time is small. Note that no extra contribution to the gradient vector is necessary because the residual used above already includes the local fit result. The sum of the two contributions, 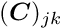 from equation (15), and
from equation (15), and 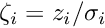 from equation (16), summed over all local fit-objects, is the final matrix of the least squares normal equations. Element
from equation (16), summed over all local fit-objects, is the final matrix of the least squares normal equations. Element 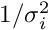 is related to the global parameters with indices and . The matrix corresponds to a simultaneous fit of the global and local parameters of all local-fit objects. The first term (15) alone corresponds to the fit, when the local parameters are assumed to be fixed; only those elements of the matrix are non-zero, where the two global parameters with indices and appear in the same measurement . In contrast, in the second term (16) those elements of the matrix are non-zero, where the two global parameters with indices and appear in the same local fit.
is related to the global parameters with indices and . The matrix corresponds to a simultaneous fit of the global and local parameters of all local-fit objects. The first term (15) alone corresponds to the fit, when the local parameters are assumed to be fixed; only those elements of the matrix are non-zero, where the two global parameters with indices and appear in the same measurement . In contrast, in the second term (16) those elements of the matrix are non-zero, where the two global parameters with indices and appear in the same local fit.
The influence of a single measurement resp. is proportional to the absolute value of the normalised residual 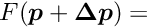 in the pure least squares fit of local-fit objects. Thus measurements with a large deviation will in general distort the resulting fit. This effect can be avoided by downweighting those measurements. Measurements with large residuals are included in the method of M-estimates by assigning to them, instead of the ideal Gaussian distribution of least squares, a different distribution with larger tails. Technically this is done by multiplying the standard weight
in the pure least squares fit of local-fit objects. Thus measurements with a large deviation will in general distort the resulting fit. This effect can be avoided by downweighting those measurements. Measurements with large residuals are included in the method of M-estimates by assigning to them, instead of the ideal Gaussian distribution of least squares, a different distribution with larger tails. Technically this is done by multiplying the standard weight 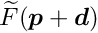 of least squares by another factor, which depends on the actual value of . This method requires an initial fit without downweighting, followed by iterative downweighting.
of least squares by another factor, which depends on the actual value of . This method requires an initial fit without downweighting, followed by iterative downweighting.
In Millepede II the local fits are improved, if necessary, by downweighting after the first iteration, with a number of iterations specified by the user with keyword outlierdownweighting {it numberofiterations}. In iterations 2 and 3 the downweighting is done with the Huber function and the Cauchy function is used, if more iterations are requested (see section Outlier treatment and debugging for an explanation of the two functions).
The aim is to find a step vector , which minimizes the objective function: 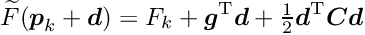 minimum. In the -th iteration the approximate solution is . A quadrative model function
minimum. In the -th iteration the approximate solution is . A quadrative model function 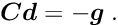
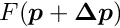
is defined with a vector . The step vector is determined as solution of the linear system
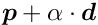
The step will minimize the quadratic function of equation (17), unless there is some inaccuracy due to rounding errors and other approximations of the matrix or the solution method. In order to get a sufficient decrease of the objective function  a line search algorithm is used.
a line search algorithm is used.
In the line search algorithm a search is made for the minimum of the function along a line  in the parameter space, where
in the parameter space, where 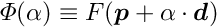 is a factor to be determined. A function
is a factor to be determined. A function 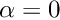 of this factor,
of this factor,
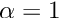
is considered. Each function evaluation at a certain value of requires one loop through the data with all local fits. The function value for 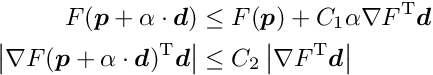 is already calculated before (start value); the first value of to be considered is
is already calculated before (start value); the first value of to be considered is 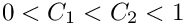 and this value is often already a sufficiently accurate minimum. In the line search algorithm the so-called strong Wolfe conditions are used; these are
and this value is often already a sufficiently accurate minimum. In the line search algorithm the so-called strong Wolfe conditions are used; these are
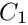
with 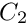 . The first condition requires a sufficient decrease of the function. The second condition, called curvature condition, ensures a slope reduction, and rules out unacceptable short steps. In practice the constant
. The first condition requires a sufficient decrease of the function. The second condition, called curvature condition, ensures a slope reduction, and rules out unacceptable short steps. In practice the constant 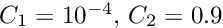 is chosen to small, for example . Typical values of the constant
is chosen to small, for example . Typical values of the constant 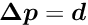 are 0.9 for a search vector by a Newton method and 0.1 for a search vector by the conjugate gradient method. Default values in Millepede II are
are 0.9 for a search vector by a Newton method and 0.1 for a search vector by the conjugate gradient method. Default values in Millepede II are 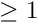 . Often only one value of , sometimes two to three values are evaluated. The last function value should never be higher than the start value.
. Often only one value of , sometimes two to three values are evaluated. The last function value should never be higher than the start value.
The global fit can be performed with a result in one step, if the matrix equation is accurately solved and if there are no outliers. The result calculated in the first data loop is usually already close to the final solution; it gives the largest reduction of the objective function. Outliers introduce some non-linearity into the problem and require iterations with repeated data loops. Another argument for repeating the steps is the non-neglectigible inaccuracy of the numerical solution of the step calculation due to rounding errors for the large number of parameters.
Iteration 0. The first data loop is called iteration 0. The function value, the first derivative vector and the second derivative matrix or an approximation to it are calculated. They allow to calculate the first step 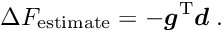 .
.
Iteration 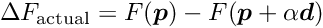 . In all further iterations a line search is performed. Starting value is the point in parameter space, obtained in the previous iteration. Each function evaluation requires a data loop with local fits. The expected decrease in an iteration can be estimated by
. In all further iterations a line search is performed. Starting value is the point in parameter space, obtained in the previous iteration. Each function evaluation requires a data loop with local fits. The expected decrease in an iteration can be estimated by
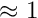
This can be compared with the actual decrease
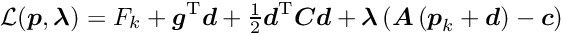
at the end of the iteration. Both values should become smaller during the iterations; convergence can be assumed if both are of the order of 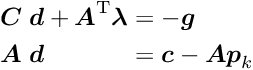 .
.
In the Lagrange multiplier method one additional parameter is introduced for each single constraint, resulting in an -vector of Lagrange multiplier. A term depending on and the constraints is added to the objective function, resulting in the Lagrange function
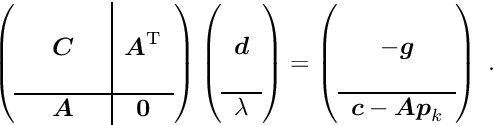
Using as before a quadratic model for the function and taking derivatives w.r.t. the parameters and the Lagrange multipliers , the two equations
are obtained; the second of these equations is the constraint equation. This system of two equations can be combined into one matrix equation

The matrix on the left hand side is still symmetric. Linear least squares problems with linear constraints can be solved directly, without iterations and without the need for initial values of the parameters. Insufficient precision of the equality constraints is corrected by the method discussed in section Feasible parameters.
Several output text file are generated in Pede. All files have a fixed name. If files with this name are existing at the Pede start, they are renamed by appending a to the file name; existing files with file name already carrying the are removed!
Log-file for Pede. The file millepede.log summarizes the job execution. Especially information on the iterations is given.
Result file. The file millepede.res contains one line per (variable or fixed) global parameter; the first three numbers have the same meaning as the lines following the Parameter keyword in the input text files. The first value is the label, the second is the fitted parameter value, and the third is the presigma, either copied from the input text file or zero (default value).
Debug file. The file mpdebug.txt, if requested by the printrecord keyword, contains detailed information of all data and fits for local-fit objects.
Eigenvector file. The file millepede.eve is written for the method diagonalization. It contains selected eigenvectors and their eigenvalues, and can be used e.g. for an analysis of weak modes.
Global parameters to be determined in a track-based alignment are mostly geometrical corrections like translation shifts and rotation angles. Usually only small corrections to the default position and angle information are necessary, and the assumption of constant first derivatives is sufficient (otherwise an iteration with creation of new data files would be necessary). In general an alignment should be done simultaneously of all relevant detectors, perhaps using structural constraints (see below).
In addition to the geometrical corrections there are several additional parameters, which determine track-hit positions like Lorentz-angle and  -values, drift-velocities etc. These parameters should be included in the alignment process, since, due to the correlation between all pairs of global parameters, a separate determination of those parameters cannot be optimal. Also beam parameters like vertex position and beam direction angles should be included in the alignment, if those value are used with the tracks. Incorrectness of the model used e.g. to calculate the expected track hit positions, for example a wrong value of the Lorentz-angle, can introduce distortions in other parameters.
-values, drift-velocities etc. These parameters should be included in the alignment process, since, due to the correlation between all pairs of global parameters, a separate determination of those parameters cannot be optimal. Also beam parameters like vertex position and beam direction angles should be included in the alignment, if those value are used with the tracks. Incorrectness of the model used e.g. to calculate the expected track hit positions, for example a wrong value of the Lorentz-angle, can introduce distortions in other parameters.
Equality constraints are, in the mathematical sense, equations between global parameters, which have to be exact (within the computing accuracy). Only linear constraints are supported. Below two areas of constraints are discussed.
A general linear transformation has 12 parameters. Three parameters of the translation and additional three parameters of a rotation are undefined, if only track residuals are minimized. At least these six parameters have to be fixed by constraining to zero the overall translation and rotation.
A large track detector has usually a sub-detector structure: the track detector is built from smaller units, which are built by smaller sub-units etc. down to the level of a single sensor. The different levels can be visualized by a tree structure. Figure 2 shows the tree structure of the cms detector.
The tree structure can be reflected in the label structure and constraints. One set of global parameters is assigned to a unit. To each of the subunits another set of global parameters; the sum of the transformations of the subunits is forced to zero by sum constraints, which remove the otherwise undefined degrees of freedom. For a unit with subunits, with for example 6 degrees of freedom, the total number of degrees of freedom becomes
![\begin{equation*} \left[ 6 + 6 \cdot N \right] \; \textrm{(parameters)} - 6 \; \textrm{(constraints)} = 6 \cdot N \; . \end{equation*}](form_281.png)
The parameters of the unit are more accurately defined than the parameters of the sub-units. Additional external measurement information from e.g. a survey can be assigned to the parameters of the unit. If all sub-unit parameters are fixed after an initial alignment, the parameters of the unit can still be variable and be improved in an alignment with a reduced total number of parameters.
Nominal transformation. For track reconstruction the local coordinate system and the global  coordinate system are used. The local system with coordinate and components
coordinate system are used. The local system with coordinate and components 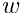 ,
, 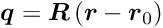 and
and 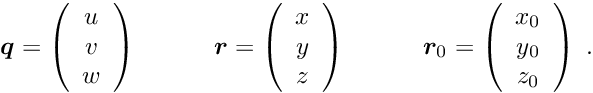 is defined w.r.t. a sensor with origin at the center of the sensor; the -axis is along the precise and the -axis is along the coarse coordinate, and the -axis is normal to the sensor. The transformation from the global to the local system is given by
is defined w.r.t. a sensor with origin at the center of the sensor; the -axis is along the precise and the -axis is along the coarse coordinate, and the -axis is normal to the sensor. The transformation from the global to the local system is given by
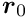
with the definitions
The nominal position  and the rotation matrix
and the rotation matrix  are determined by detector assembly and survey information. The convention is to use the three Euler angles
are determined by detector assembly and survey information. The convention is to use the three Euler angles  ,
, 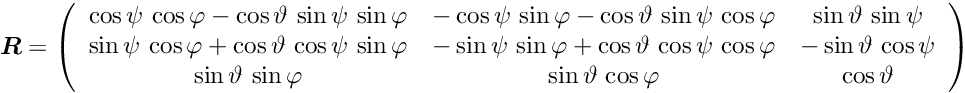 and
and 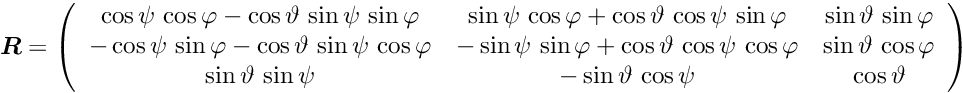 to determine the nominal rotation matrix :
to determine the nominal rotation matrix :
or
The ranges of the angles are: 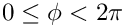 ,
, 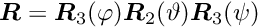 , and
, and 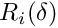 .
.
A different convention is to parametrize the rotation by Euler angles , and with the rotation 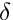 , where
, where 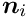 is a rotation by an angle
is a rotation by an angle 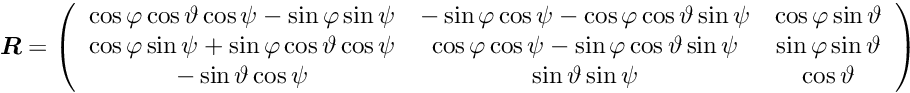 about the axis
about the axis  . The rotation is
. The rotation is
The ranges of the angles are: , and .
Alignment correction to the transformation. The alignment procedure determines a correction to the nominal transformation by an incremental rotation 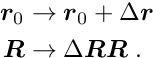 and a translation
and a translation  . The combined translation and rotation becomes
. The combined translation and rotation becomes
The correction matrix is given by small rotations by  , \,
, \, 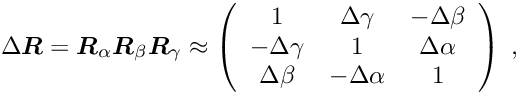 and
and  around the -axis, the (new) -axis and the (new) -axis:
around the -axis, the (new) -axis and the (new) -axis:
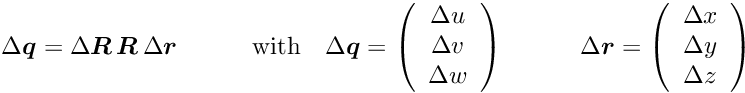
where the approximation has sufficient accuracy for small angles , \, and . The position correction 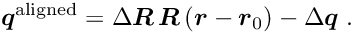 transforms to the local system as
transforms to the local system as
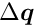
These corrections define the corrected (aligned) transformation from global to local coordinates:
The task of the alignment by tracks is to determine the correction angles , and (and thus the rotation matrix ) and the translation vector or vector 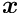 for each individual detector element.
for each individual detector element.
Markus Stoye has worked with different versions of Millepede II during the development phase in the last two years in alignment studies for the inner tracker of the cms experiment. I would like to thank him for the close collaboration, which was essential for the development of Millepede II. I would like to thank also Gero Flucke, who contributed the C 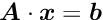 code, and Claus Kleinwort for the Millepede I/II comparison using data from the H1 experiment.
code, and Claus Kleinwort for the Millepede I/II comparison using data from the H1 experiment.