|
Millepede-II V04-17-06
|
|
Millepede-II V04-17-06
|
Major changes with respect to the draft manual.
The entries cut has now three arguments:
iarg3 (iteren=mreqenf*iarg3): Iteration of entries cut. It can be problematic if different global parameters related to the same measurements get different (number of) entries. If some are below and some are above mreqenf some are fixed and some are variable which may not make sense. An example is the rigid body alignment of a planar silicon pixel sensor in the local (uvw) system. For the two indendent measurements (in u and v) the corresponding alignment offsets (du, dv) appear each only for one measurement. The offset perpendicular to the sensor plane (dw) and the rotations affect both measurement. Therefore the offsets (du, dv) have a factor two smaller number of entries as the other four. To handle this situation the entries cut (on the binary files) can be iterated: If in a measurement some global parameters are fixed (due to entries < mreqenf) for the other parameters the cut value is increased by the constant factor iarg3. For the axample above a factor two would be appropriate (all six parameters fixed now).
Another option to avoid this problem is to not count the entries on the level of equations (measurements) but on the level of records (tracks): countrecords
A third option is to produce the binary files without zero supression (of global derivatives).
The following methods to obtain the solution 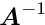 from a linear equation system
from a linear equation system 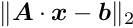 are implemented:
are implemented:
The solution and the covariance matrix 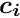 are obtained by inversion of
are obtained by inversion of  . Available are the value, error and global correlation for all global parameters. The matrix inversion routine has been parallelized and can be used for up to several 10000 parameters.
. Available are the value, error and global correlation for all global parameters. The matrix inversion routine has been parallelized and can be used for up to several 10000 parameters.
The solution and the covariance matrix are obtained by diagonalization of . Available are the value, error, global correlation and eigenvalue (and eigenvector) for all global parameters.
The solution is obtained by minimizing 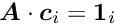 iteratively and is only approximate. MINRES [ref 8] is a special case of the generalized minimal residual method (GMRES) for symmetric matrices. Preconditioning with a band matrix of zero or finite bandwidth is possible. Individual columns
iteratively and is only approximate. MINRES [ref 8] is a special case of the generalized minimal residual method (GMRES) for symmetric matrices. Preconditioning with a band matrix of zero or finite bandwidth is possible. Individual columns 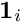 of the covariance matrix can be calculated by solving
of the covariance matrix can be calculated by solving 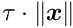 where
where 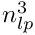 is the i-th column on the unit matrix. The most time consuming part (product matrix times vector per iteration) has been parallelized. Available are the value for all (and optionally error, global correlation for few) global parameters.
is the i-th column on the unit matrix. The most time consuming part (product matrix times vector per iteration) has been parallelized. Available are the value for all (and optionally error, global correlation for few) global parameters.
The MINRES-QLP implementation [ref 9] is a MINRES evolution with improved norm estimates and stopping conditions (leading potentially to different numbers of internal iterations). Internally it uses QLP instead of the QR factorization in MINRES which should be numerically superior and allows to find for singular systems the minimal length (pseudo-inverse) solution.
The default behavior is to start (the internal iterations) with QR factorization and to switch to QLP if the (estimated) matrix condition exceeds mrtcnd. Pure QR or QLP factorization can be enforced by mrmode.
As alternative to the Lagrange multiplier method the solution by elimination has been added for problems with linear equality constraints. A QL factorization (with Householder reflections) of the transposed constraints matrix is used to transform to an unconstrained problem. For sparse matrix storage the sparsity of the global matrix is preserved.
The solution is obtained by a root-free Cholesky decomposition (LDLt). The covarinance matrix is not being calclulated. The method ia about a factor 2-3 faster than inversion (according to several tests). It is restricted to solution by elimination for problems with linear equality constraints (requires positive definite matrix). Supports block matrix storage for disjoint parameter blocks.
For these optional methods the solution is obtained by matrix factorization from an external LAPACK library. There exist (open or proprietary) implementations heavily optimized for specific hardware (and partially multi-threaded) which could easily be an order of magnitude faster than e.g. the custom code used for decomposition. Tested has been the Intel MKL and OpenBLAS.
The symmetric global matrix can be stored in packed triangular (similar to full for inversion etc) or unpacked quadaratic shape. For unpacked storage the elimination of constraints is implemented with LAPACK (DGEQLF, DORMQL) as alternative.
For positive definite matrices (elimination of constraints) a Cholesky factorization is used (DPPTRF/DPOTRF) and for indefinite matrices (Lagrange multipliers for constraints) a Bunch-Kaufman factorization (DSPTRF/DSYTRF). With the option LAPACKwitherrors the inverse matrix is calculated from the factorization to provide parameter errors (DPPTRI/DPOTRI, DSPTRI/DSYTRI, potentially slow, single-threaded).
This optional method is using the Intel oneMKL PARDISO shared-memory multiprocessing parallel direct sparse solver. This aims at use cases with really sparse global matrices (e.g. less than 10% nonzero elements).
The upper triangle of the (symmetric) global matrix is stored in the 3-array variation of the compressed sparse row format (CSR3). It can be checked for a (fixed size) block structure to reduce the storage size (BSR3). (This could be further improved by reordering - not implemeted.)
For problems with linear equality constraints the usage of Lagrange multipliers is enforced.
For the internal steering parameters IPARM(64) the default values are used. They can be modified with the pardiso keyword (specifying pairs of indices (1-64) and values):
pardiso
... ...
index value
... ...
Related options:
blocksizePARDISO 2 3 4 6 9 12
Optionally a term 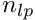 can be added to the objective function (to be minimized) where is the vector of global parameters weighted with the inverse of their individual pre-sigma values.
can be added to the objective function (to be minimized) where is the vector of global parameters weighted with the inverse of their individual pre-sigma values.
In case the local fit is a track fit with proper description of multiple scattering in the detector material additional local parameters have to be introduced for each scatterer and solution by inversion can get time consuming (~ 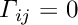 for
for 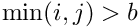 local parameters). For trajectories based on broken lines [ref 4,6] the corresponding matrix
local parameters). For trajectories based on broken lines [ref 4,6] the corresponding matrix 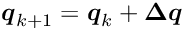 has a bordered band structure (
has a bordered band structure ( 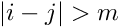 for
for 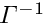 (border size) and
(border size) and 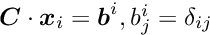 (bandwidth)). With root-free Cholesky decomposition the time for the solution is linear and for the calculation of
(bandwidth)). With root-free Cholesky decomposition the time for the solution is linear and for the calculation of 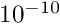 (needed for the construction of the global matrix) quadratic in . The condition of the diagonal matrix from the decomposition (of the band part) can be used to reject ill conditioned cases (see maxlocalcond). For each local fit the structure of is checked and the faster solution method selected automatically.
(needed for the construction of the global matrix) quadratic in . The condition of the diagonal matrix from the decomposition (of the band part) can be used to reject ill conditioned cases (see maxlocalcond). For each local fit the structure of is checked and the faster solution method selected automatically.
The code has been largely parallelized using OpenMP™. This includes the reading of binary files, the local fits, the construction of the sparsity structure and filling of the global matrix and the global fit (except by diagonalization). The number of threads is set by the command threads.
The OpenMP environment can be displayed with:
export OMP_DISPLAY_ENV=TRUE
Caching. The records are read in blocks into a read cache and processed from there in parallel, each record by a single thread. For the filling of the global matrix the (zero-compressed) update matrices ( 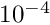 from equations (15), (16)) produced by each local fit are collected in a write cache. After processing the block of records this is used to update the global matrix in parallel, each row by a single thread. The total cache size can be changed by the command cache.
from equations (15), (16)) produced by each local fit are collected in a write cache. After processing the block of records this is used to update the global matrix in parallel, each row by a single thread. The total cache size can be changed by the command cache.
In sparse storage mode for each row the list of column indices (and values) for the non-zero elements are stored. With compression regions of continous column indices are represented by the first index and their number (packed into a single 32bit integer). Compression is selected by the command compress. In addition rare elements can be neglected (,histogrammed) or stored in single instead of double precision according to the pairentries command.
With the implementation of parameter groups (sets of adjacent global parameters (labels) appearing in the binary files always together) the sparsity structure addresses not single values anymore but block matrices with sizes according to the contributing parameter groups. Groups with adjacent column ranges are combined into a single block matrix. The offset and first column index in a (block) row is stored.
The zlib can be used to directly read gzipped C binary files. In this case reading with multiple threads (each file by single thread) can speed up the decompression.
A constant weight can be applied to all records in a binary file:
<file name> -- <weight> ! <comment>
The Millepede source code has been formally transformed from fixed form FORTRAN77 to free form Fortran90 (using TO_F90 by Alan Miller) and (most parts) modernized:
IMPLICIT NONE everywhere. Unused variables removed.COMMON blocks replaced by MODULEs.GOTOs replaced by proper DO loops.INTENT (input/output) of arguments described.Unused parts of the code (like the interactive mode) have been removed. The reference compiler for the Fortran90 version is gcc-4.6.2 (gcc-4.4.4 works too).
The memory management for dynamic data structures (matrices, vectors, ..) has been changed from a subdivided static COMMON block to dynamic (ALLOCATABLE) Fortran90 arrays. One Pede executable is now sufficient for all application sizes.
In the first loop over all binary files a preset read buffer size is used. Too large records are skipped, but the maximal record length is still being updated. If any records had to be skipped the read buffer size is afterwards adjusted according to the maximal record length and the first loop is repeated.
The number of binary files has no hard-coded limit anymore, but is calculated from the steering file and resources (file names, descriptors, ..) are allocated dynamically. Some resources may be limited by the system.
The Pede executable can be run in special modes to only check the input without producing a solution. This can be useful in case of problems. Checked are the global parameters and their (equality) constraints from the steering and binary files. Debug information is written to the standard output and the millepede.res text file.
Basic checks: Command 'checkinput 1' or command line option '-c'
To standard output:
To text file:
!>'.More checks: Command 'checkinput 2' or command line option '-C'
Additionally to standard output:
Additionally to text file:
For each global parameter a brief comment can be defined to annotate the millepede.res text file. The syntax is similar as for the "Parameter" or "Constraint" keywords:
Comment
... ...
label text
... ...