Experiment setup
Cheetah does not magically know the details about your experiment - it is necessary to tell Cheetah about the location and format of data files, detector calibration, and what analysis to perform.
Most of this mess has been hidden behind a few configuration scripts which you will need to edit in order to provide the necessary information. This page will guide you through the key steps in setting up these scripts from scratch for a new experiment.
First, know the location of your data and where temporary files can be written.
At CXI, all data for your experiment will usually be in a location such as
/reg/d/psdm/cxi/cxi12345
In this directory will be subdirectories with the raw data (xtc/), somewhere to write temporary files (scratch/), and a few other directories that don’t matter for now.
[psexport02] cxi12345 > ls
calib ftc hdf5 res scratch usr xtc
1. Download the template
Expand the file /reg/g/cfel/cheetah/template.tar into the location where you want files to be placed:
> tar -xvf /reg/g/cfel/cheetah/template.tar
This will create the cheetah directory with a number of sub-directories containing a ‘starter kit’ of files:
> ls cheetah
calib gui hdf5 process
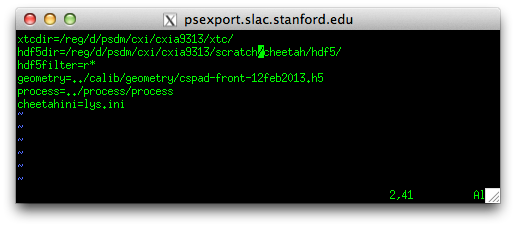
2. edit gui/crawler.config
Edit the file cheetah/gui/crawler.config
xtcdir should point to the location of your XTC files
hdf5dir should point to where you want the Cheetah output to go. By default let this be the cheetah/hdf5 directory expanded by the template (but it can be elsewhere).
The rest can be left alone for now.
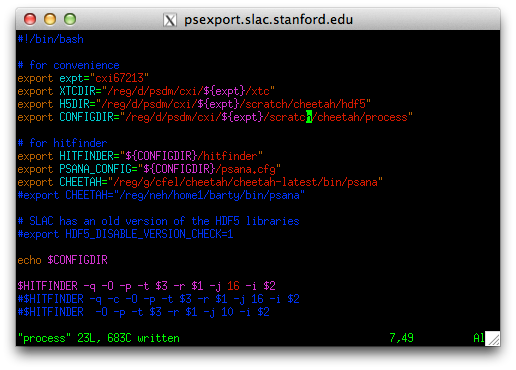
3. edit process/process
Edit the file cheetah/process/process
This script is a front-end to making Cheetah run, enabling data to be processed from the command line by simply typing the one-line command
> ./process <Run#> <cheetah.ini> <tag>
This is the command executed by the ‘Run Cheetah’ button on the front of the GUI.
It should only be necessary to edit the experiment name. The rest should should not need modification, but should be self-explanatory if changes need to be made (for example configuration files in ${expt}/res instead of ${expt}/scratch).
The last three lines are various options for calling the hitfinder script using either (i) the SLAC batch queue, (ii) the SLAC batch queue with a separate job for each XTC stream, or (iii) output to the terminal. Probably no need to change these (ii adds some speed at the expense of complexity, while option iii is useful for debugging if things go really wrong)
Actual details of the job submission process are hidden in the script hitfinder. Probably no need to to touch the hitfinder script at all unless there are problems with how jobs are submitted to the batch queue (search for lines containing ‘bsub’).
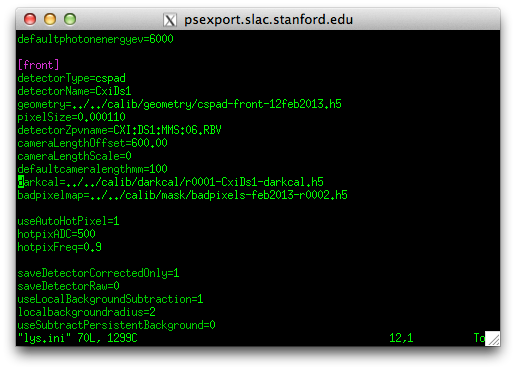
Configuring what Cheetah does is done by editing the cheetah.ini file.
There is a sample nanocrystal analysis file in process/lys.ini, and will look for Bragg peaks to find hits.
Open this file and edit it.
In particular, change the line starting with “darkcal=” to point to the dark calibration file you just created.
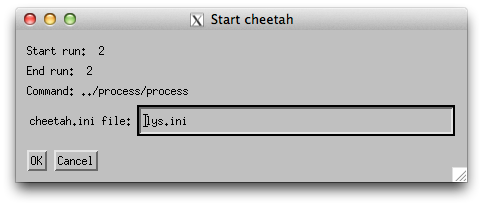
Select a run with data and click the “Run Cheetah” button and specify ‘lys.ini’ as the configuration file
(it is possible to select more than one run at a time).
And things should start to happen.
Once again jobs should appear in the batch queue
> bjobs -u all -q psfehq
690066 barty RUN psfehq psexport02 6*psana1311 r0001 Oct 23 07:3
If the crawler is running, the Cheetah status and number of processed frames should update periodically
Data should start to appear in the cheetah/hdf5 directory
If not, something is wrong and it’s time for debugging. In particular look at the output of hdf5/run0xxx/bsub.log.
The setup is now done and it’s time for optimisation of the output.
4. Start the gui
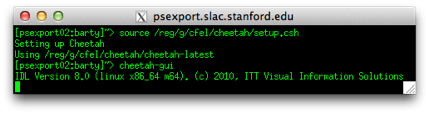
Start the GUI interface using the cheetah-gui command as described on the getting started page.

Click the IDL virtual machine box to dismiss it.
(The Cheetah GUI uses the IDL virtual machine as an environment, which can be downloaded and used for free if you want to run the image browser at home.)
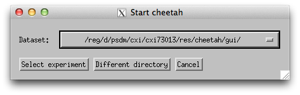
You should then be presented with a list of all previous experiments.
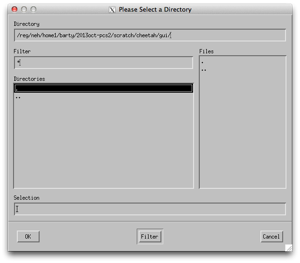
Either select one of the existing experiments, or use ‘Different Directory’ to navigate to the location of the cheetah/gui folder described above and click OK.
This should bring up the interface shown on the getting started page.
This should be sufficient to view an existing data set set up by someone else.
4. enabling command operations and the crawler
Processing of data and updating of the GUI table as an experiment progresses requires the crawler to be started. This little process runs in the background gathering information on the status of XTC files available on disk and the progress of Cheetah jobs. It can overwrite the current table contents, and only one person should run this at any one time (even though many people can view the GUI at once).
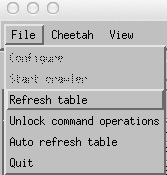
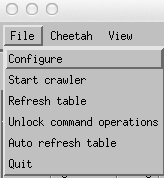
To start the crawler it is first necessary to go
File->Unlock command operations
then
File->Start Crawler
Unlocking command operations enables the Crawler option and the “Run Cheetah” button. This step is deliberately added in order to force one to think before overwriting existing data.
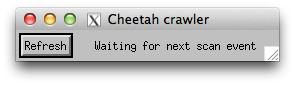
A little window with the crawler should appear on screen. Look in the terminal for any errors.
4. create a dark calibration file
The detector needs to be corrected for static offsets, often known as ‘dark frames’. Make sure to take one at the start of the experiment and every few hours during the experiment.
Click the “Run Cheetah” button and specify ‘darkcal.ini’ as the configuration file.
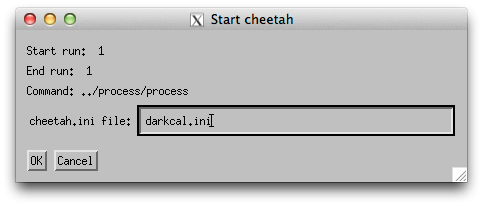
The job should now be go to the batch queue for processing.
Jobs should appear in the batch queue
> bjobs -u all -q psfehq
690066 barty RUN psfehq psexport02 6*psana1311 r0001 Oct 23 07:3
If the crawler is running, the Cheetah status and number of processed frames should update periodically
Data should start to appear in the cheetah/hdf5 directory
In particular, a file called r00xx-CxiDs1-darkcal.h5 should start to appear.
If not, something is wrong and it’s time for debugging
If all goes well, wait for the job to finish then copy the file r00xx-CxiDs1-darkcal.h5 into the cheetah/calib/darkcal directory.
4. Edit your cheetah.ini file
4. Time for a cuppa
Setup of the guI should now be done and it’s time for optimisation of the output.
Before we go, a few hints:
-
1)It is convenient to start a new .ini file for each type of sample. The name of the .ini file is used by the GUI to tag runs and update the table, and ends up as the tag name on the HDF5 directories created. Separate names helps keep separate samples apart, and makes it easy to copy/tar/grep directories based on sample name or other eperiment parameters. This helps keep things organised. Use a symbolic link if the files are really the same.
-
2)Review your output. Often. No analysis should ever be done completely blind. Use the ‘Show hits” button to look at images and refine the hit finding parameters.